1 Introduction to Data
This section is adapted from the Introduction to Statistics for the Life and Biomedical Sciences2
Packages used in this Section
pacman::p_load(
openintro,
oibiostat, # devtools::install_github("OI-Biostat/oi_biostat_data")
ggplot2,
ggpubr,
DT,
kableExtra
)1.1 Case Study: preventing peanut allergies
The proportion of young children in Western countries with peanut allergies has doubled in the last 10 years. Previous research suggests that exposing infants to peanut-based foods, rather than excluding such foods from their diets, may be an effective strategy for preventing the development of peanut allergies. The Learning Early about Peanut Allergy (LEAP) study was conducted to investigate whether early exposure to peanut products reduces the probability that a child will develop peanut allergies.3
The study team enrolled children in the United Kingdom between 2006 and 2009, selecting 640 infants with eczema, egg allergy, or both. Each child was randomly assigned to either the peanut consumption (treatment) group or the peanut avoidance (control) group. Children in the treatment group were fed at least 6 grams of peanut protein daily until 5 years of age, while children in the control group avoided consuming peanut protein until 5 years of age.
At 5 years of age, each child was tested for peanut allergy using an oral food challenge (OFC): 5 grams of peanut protein in a single dose. A child was recorded as passing the oral food challenge if no allergic reaction was detected, and failing the oral food challenge if an allergic reaction occurred. These children had previously been tested for peanut allergy through a skin test, conducted at the time of study entry; the main analysis presented in the paper was based on data from 530 children with an earlier negative skin test. Although a total of 542 children had an earlier negative skin test, data collection did not occur for 12 children.
Individual-level data from the study are shown in Figure 1.1. Each row represents a participant and shows the participant’s study ID number, treatment group assignment, and OFC outcome. The data are available as from the oibiostat R package.
data(LEAP)Figure 1.1: Individual-level LEAP results
The data can be organized in the form of a two-way summary table; Table 1.1 shows the results categorized by treatment group and OFC outcome.
stats::addmargins(base::table(LEAP$treatment.group, LEAP$overall.V60.outcome)) | FAIL OFC | PASS OFC | Sum | |
|---|---|---|---|
| Peanut Avoidance | 36 | 227 | 263 |
| Peanut Consumption | 5 | 262 | 267 |
| Sum | 41 | 489 | 530 |
The summary Table 1.1 makes it easier to identify patterns in the data. Recall that the question of interest is whether children in the peanut consumption group are more or less likely to develop peanut allergies than those in the peanut avoidance group. In the avoidance group, the proportion of children failing the OFC is \(36/263 = 0.137\) (13.7%); in the consumption group, the proportion of children failing the OFC is \(5/267 = 0.019\) (1.9%). Figure 1.2 shows a graphical method of displaying the study results, using either the number of individuals per category from Table 1.1 or the proportion of individuals with a specific OFC outcome in a group.
ggplot(data = LEAP, aes(x = treatment.group, fill = overall.V60.outcome)) +
geom_bar(position = position_stack(reverse = TRUE)) +
theme(legend.position = "top") + ggpubr::theme_pubr() +
scale_fill_openintro()
ggplot(data = LEAP, aes(x = treatment.group, fill = overall.V60.outcome)) +
geom_bar(position = position_fill(reverse = TRUE)) +
theme(legend.position = "top") + ggpubr::theme_pubr() +
scale_fill_openintro()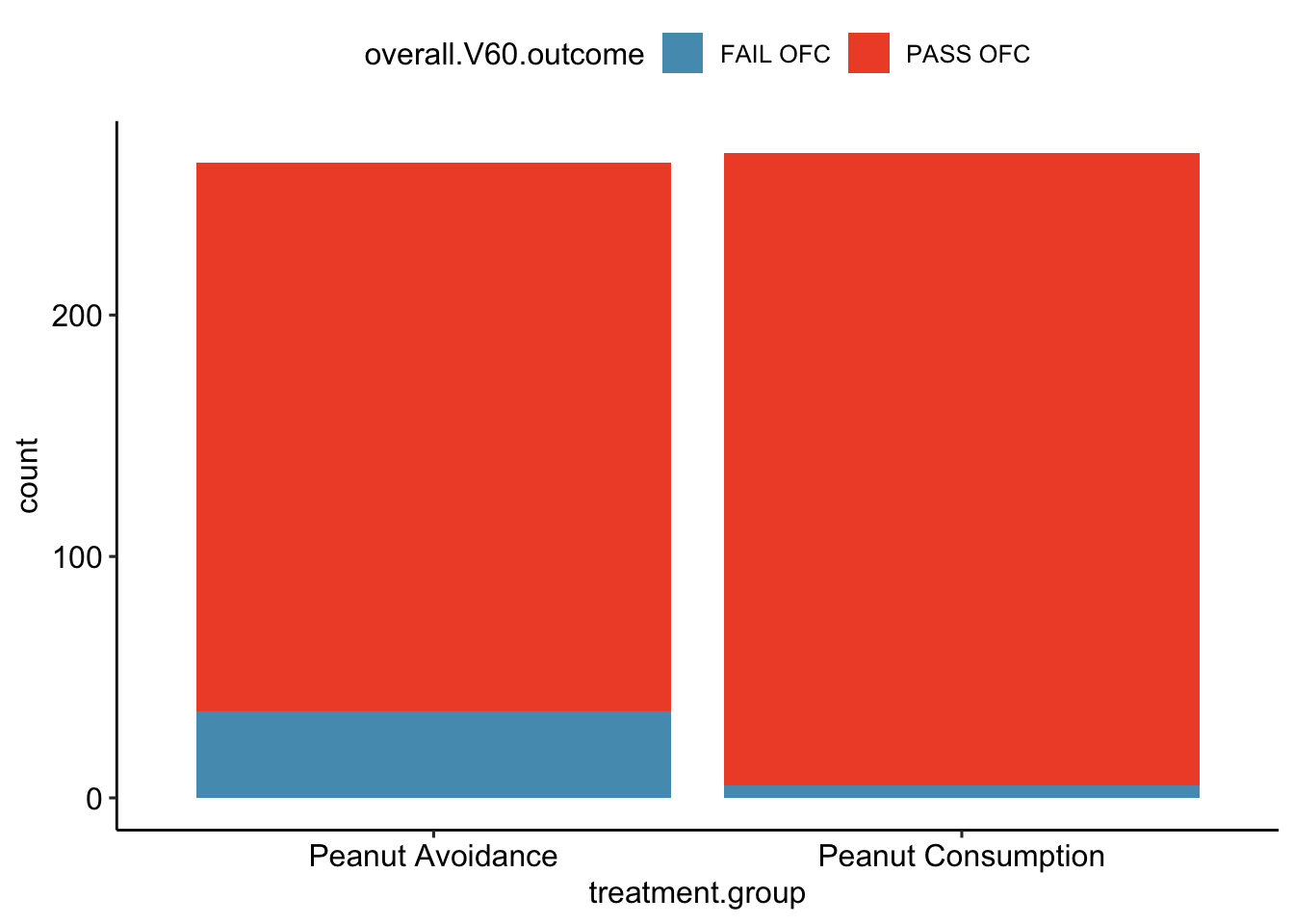
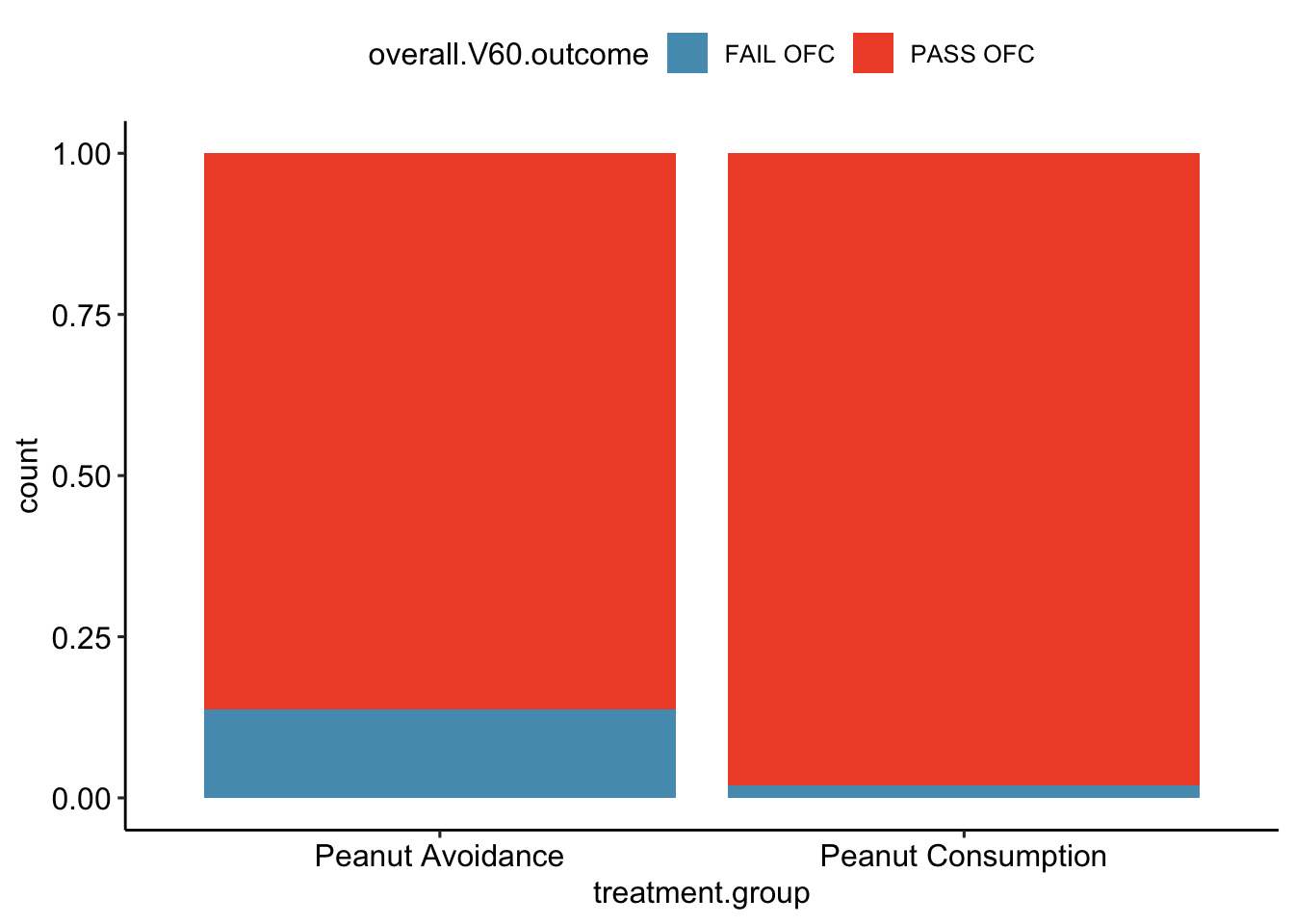
Figure 1.2: (top) A bar plot displaying the number of individuals who failed or passed the OFC in each treatment group. (bottom) A bar plot displaying the proportions of individuals in each group that failed or passed the OFC.
The proportion of participants failing the OFC is 11.8% higher in the peanut avoidance group than the peanut consumption group. Another way to summarize the data is to compute the ratio of the two proportions (0.137/0.019 = 7.31), and conclude that the proportion of participants failing the OFC in the avoidance group is more than 7 times as large as in the consumption group; i.e., the risk of failing the OFC was more than 7 times as great for participants in the avoidance group relative to the consumption group.
Based on the results of the study, it seems that early exposure to peanut products may be an effective strategy for reducing the chances of developing peanut allergies later in life. It is important to note that this study was conducted in the United Kingdom at a single site of pediatric care; it is not clear that these results can be generalized to other countries or cultures.
The results also raise an important statistical issue: does the study provide definitive evidence that peanut consumption is beneficial? In other words, is the 11.8% difference between the two groups larger than one would expect by chance variation alone? The material on inference in later chapters will provide the statistical tools to evaluate this question.
1.2 Data basics
Effective organization and description of data is a first step in most analyses. This section introduces a structure for organizing data and basic terminology used to describe data.
1.2.1 Observations, variables, and data matrices
In evolutionary biology, parental investment refers to the amount of time, energy, or other resources devoted towards raising offspring. This section introduces the frog dataset, which originates from a 2013 study about maternal investment in a frog species.4 Reproduction is a costly process for female frogs, necessitating a trade-off between individual egg size and total number of eggs produced. Researchers were interested in investigating how maternal investment varies with altitude and collected measurements on egg clutches found at breeding ponds across 11 study sites; for 5 sites, the body size of individual female frogs was also recorded.
Figure 1.3: Data matrix for the frog dataset.
Figure 1.3 displays rows 1, 2, 3, and 150 of the data from the 431 clutches
observed as part of the study. The frog dataset is available from the oibiostat R package. Each row in the table corresponds to a single clutch, indicating where the clutch was collected (altitude and latitude), egg.size, clutch.size, clutch.volume, and body.size of the mother when available. An empty cell corresponds to a missing value, indicating that information on an individual female was not collected for that particular clutch. The recorded characteristics are referred to as variables; in this table, each column represents a variable.
| variable | description |
|---|---|
altitude |
Altitude of the study site in meters above sea level |
latitude |
Latitude of the study site measured in degrees |
egg.size |
Average diameter of an individual egg to the 0.01 mm |
clutch.size |
Estimated number of eggs in clutch |
clutch.volume |
Volume of egg clutch in mm |
body.size |
Length of mother frog in cm |
It is important to check the definitions of variables, as they are not always obvious. For example, why has clutch.size not been recorded as whole numbers? For a given clutch, researchers counted approximately 5 grams’ worth of eggs and then estimated the total number of eggs based on the mass of the entire clutch. Definitions of the variables are given in the Table above.
The data in Figure 1.3 form a data frame and, in this example, are organized in tidy format. Each row of a tidy data frame corresponds to an observational unit, and each column corresponds to a variable. A piece of the data frame for the LEAP study introduced in Section 1.1 is shown in Figure 1.1; the rows are study participants and three variables are shown for each participant. Tidy data frames are a convenient way to record and store data. If the data are collected for another individual, another row can easily be added; similarly, another column can be added for a new variable.
1.2.2 Types of variables
The Functional polymorphisms Associated with human Muscle Size and Strength study (FAMuSS) measured a variety of demographic, phenotypic, and genetic characteristics for about 1,300 participants.5 Data from the study have been used in a number of subsequent studies, such as one examining the relationship between muscle strength and genotype at a location on the ACTN3 gene.6
The famuss dataset is a subset of the data for 595 participants.7 The famuss dataset from the oibiostat package is shown in Figure 1.4, and the variables are described in the Table below.
data("famuss")Figure 1.4: Data matrix for the famuss dataset.
| variable | description |
|---|---|
sex |
Sex of the participant |
age |
Age in years |
race |
Race, recorded as African Am (African American), Caucasian, Asian, Hispanic or Other
|
height |
Height in inches |
weight |
Weight in pounds |
actn3.r577x |
Genotype at the location r577x in the ACTN3 gene. |
ndrm.ch |
Percent change in strength in the non-dominant arm, comparing strength after to before training |
The variables age, height, weight, and ndrm.ch are numerical variables. They take on numerical values, and it is reasonable to add, subtract, or take averages with these values. In contrast, a variable reporting telephone numbers would not be classified as numerical, since sums, differences, and averages in this context have no meaning. Age measured in years is said to be discrete, since it can only take on numerical values with jumps; i.e., positive integer values. Percent change in strength in the non-dominant arm (ndrm.ch) is continuous, and can take on any value within a specified range.
The variables sex, race, and actn3.r577x are categorical variables, which take on values that are names or labels. The possible values of a categorical variable are called the variable’s levels. For example, the levels of actn3.r577x are the three possible genotypes at this particular locus: CC, CT, or TT. Categorical variables without a natural ordering are called nominal categorical variables; sex, race, and actn3.r577x are all nominal categorical variables. Categorical variables with levels that have a natural ordering are referred to as ordinal categorical variables. For example, age of the participants grouped into 5-year intervals (15-20, 21-25, 26-30, etc.) is an ordinal categorical variable.
Categorical variables are sometimes called factor variables.
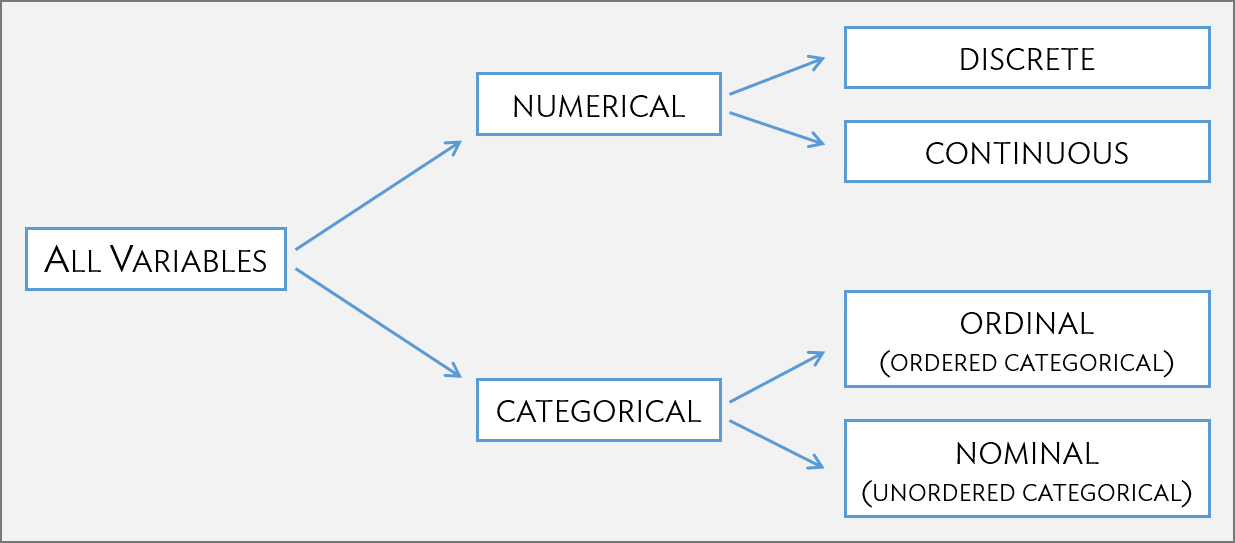
Figure 1.5: Breakdown of variables into their respective types.
1.2.3 Relationships between variables
Many studies are motivated by a researcher examining how two or more variables are related. For example, do the values of one variable increase as the values of another decrease? Do the values of one variable tend to differ by the levels of another variable?
One study used the famuss data to investigate whether ACTN3 genotype at a particular location (residue 577) is associated with change in muscle strength. The ACTN3 gene codes for a protein involved in muscle function. A common mutation in the gene at a specific location changes the cytosine (C) nucleotide to a thymine (T) nucleotide; individuals with the TT genotype are unable to produce any ACTN3 protein.
Researchers hypothesized that genotype at this location might influence muscle function. As a measure of muscle function, they recorded the percent change in non-dominant arm strength after strength training; this variable, ndrm.ch, is the response variable in the study. A response variable is defined by the particular research question a study seeks to address, and measures the outcome of interest in the study. A study will typically examine whether the values of a response variable differ as values of an explanatory variable change, and if so, how the two variables are related. A given study may examine several explanatory variables for a single response variable. The explanatory variable examined in relation to ndrm.ch in the study is actn3.r557x, ACTN3 genotype at location 577.
Response variables are sometimes called dependent variables and explanatory variables are often called independent variables or predictors.
1.3 Data collection principles
The first step in research is to identify questions to investigate. A clearly articulated research question is essential for selecting subjects to be studied, identifying relevant variables, and determining how data should be collected.
1.3.1 Populations and samples
Consider the following research questions:
- Do bluefin tuna from the Atlantic Ocean have particularly high levels of mercury, such that they are unsafe for human consumption?
- For infants predisposed to developing a peanut allergy, is there evidence that introducing peanut products early in life is an effective strategy for reducing the risk of developing a peanut allergy?
- Does a recently developed drug designed to treat glioblastoma, a form of brain cancer, appear more effective at inducing tumor shrinkage than the drug currently on the market?
Each of these questions refers to a specific target population. For example, in the first question, the target population consists of all bluefin tuna from the Atlantic Ocean; each individual bluefin tuna represents a case. It is almost always either too expensive or logistically impossible to collect data for every case in a population. As a result, nearly all research is based on information obtained about a sample from the population. A sample represents a small fraction of the population. Researchers interested in evaluating the mercury content of bluefin tuna from the Atlantic Ocean could collect a sample of 500 bluefin tuna (or some other quantity), measure the mercury content, and use the observed information to formulate an answer to the research question.
1.3.2 Anecdotal evidence
Anecdotal evidence typically refers to unusual observations that are easily recalled because of their striking characteristics. Physicians may be more likely to remember the characteristics of a single patient with an unusually good response to a drug instead of the many patients who did not respond. The dangers of drawing general conclusions from anecdotal information are obvious; no single observation should be used to draw conclusions about a population.
While it is incorrect to generalize from individual observations, unusual observations can sometimes be valuable. E.C. Heyde was a general practitioner from Vancouver who noticed that a few of his elderly patients with aortic-valve stenosis (an abnormal narrowing) caused by an accumulation of calcium had also suffered massive gastrointestinal bleeding. In 1958, he published his observation.8 Further research led to the identification of the underlying cause of the association, now called Heyde’s Syndrome.9
An anecdotal observation can never be the basis for a conclusion, but may well inspire the design of a more systematic study that could be definitive.
1.3.3 Sampling from a population
Sampling from a population, when done correctly, provides reliable information about the characteristics of a large population. The US Centers for Disease Control (US CDC) conducts several surveys to obtain information about the US population, including the Behavior Risk Factor Surveillance System (BRFSS) (https://www.cdc.gov/brfss/index.html). The BRFSS was established in 1984 to collect data about health-related risk behaviors, and now collects data from more than 400,000 telephone interviews conducted each year. The CDC conducts similar surveys for diabetes, health care access, and immunization. Likewise, the World Health Organization (WHO) conducts the World Health Survey in partnership with approximately 70 countries to learn about the health of adult populations and the health systems in those countries (http://www.who.int/healthinfo/survey/en/).
The general principle of sampling is straightforward: a sample from a population is useful for learning about a population only when the sample is representative of the population. In other words, the characteristics of the sample should correspond to the characteristics of the population.
Suppose that the quality improvement team at an integrated health care system, such as Harvard Pilgrim Health Care, is interested in learning about how members of the health plan perceive the quality of the services offered under the plan. A common pitfall in conducting a survey is to use a convenience sample, in which individuals who are easily accessible are more likely to be included in the sample than other individuals. If a sample were collected by approaching plan members visiting an outpatient clinic during a particular week, the sample would fail to enroll generally healthy members who typically do not use outpatient services or schedule routine physical examinations; this method would produce an unrepresentative sample (Figure 1.6).
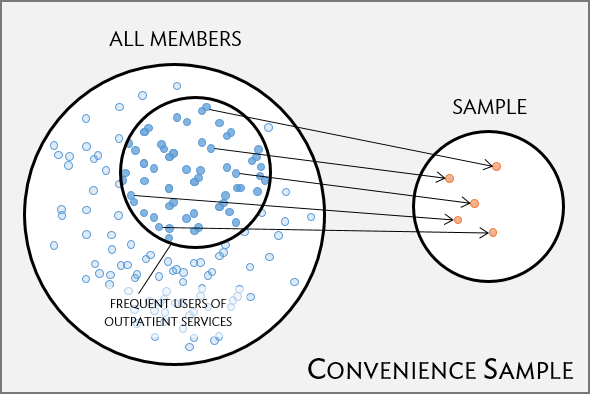
Figure 1.6: Instead of sampling from all members equally, approaching members visiting a clinic during a particular week disproportionately selects members who frequently use outpatient services.
Random sampling is the best way to ensure that a sample reflects a population. In a simple random sample (SRS), each member of a population has the same chance of being sampled. One way to achieve a simple random sample of the health plan members is to randomly select a certain number of names from the complete membership roster, and contact those individuals for an interview (Figure 1.7).
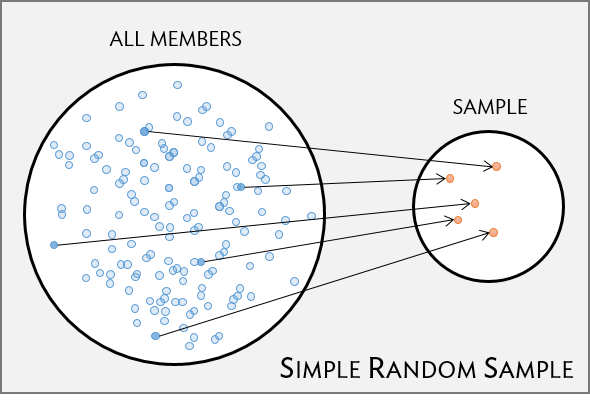
Figure 1.7: Five members are randomly selected from the population to be interviewed.
Even when a simple random sample is taken, it is not guaranteed that the sample is representative of the population. If the non-response rate for a survey is high, that may be indicative of a biased sample. Perhaps a majority of participants did not respond to the survey because only a certain group within the population is being reached; for example, if questions assume that participants are fluent in English, then a high non-response rate would be expected if the population largely consists of individuals who are not fluent in English (Figure 1.8). Such non-response bias can skew results; generalizing from an unrepresentative sample may likely lead to incorrect conclusions about a population.
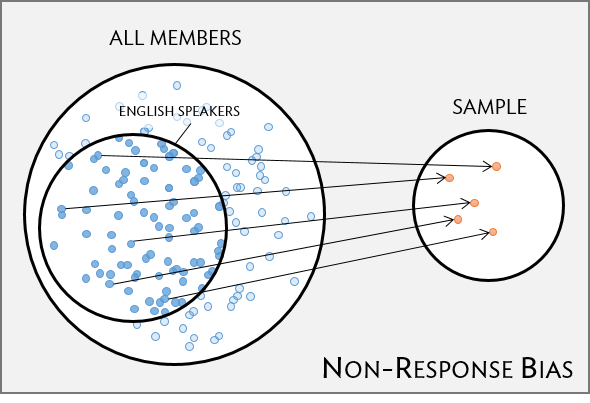
Figure 1.8: Surveys may only reach a certain group within the population, which leads to non-response bias. For example, a survey written in English may only result in responses from health plan members fluent in English.
1.3.4 Sampling methods
Almost all statistical methods are based on the notion of implied randomness. If data are not sampled from a population at random, these statistical methods – calculating estimates and errors associated with estimates – are not reliable. Four random sampling methods are discussed in this section: simple, stratified, cluster, and multistage sampling.
In a simple random sample, each case in the population has an equal chance of being included in the sample (Figure 1.9). Under simple random sampling, each case is sampled independently of the other cases; i.e., knowing that a certain case is included in the sample provides no information about which other cases have also been sampled.
In stratified sampling, the population is first divided into groups called strata before cases are selected within each stratum (typically through simple random sampling) (Figure 1.9). The strata are chosen such that similar cases are grouped together. Stratified sampling is especially useful when the cases in each stratum are very similar with respect to the outcome of interest, but cases between strata might be quite different.
Suppose that the health care provider has facilities in different cities. If the range of services offered differ by city, but all locations in a given city will offer similar services, it would be effective for the quality improvement team to use stratified sampling to identify participants for their study, where each city represents a stratum and plan members are randomly sampled from each city.
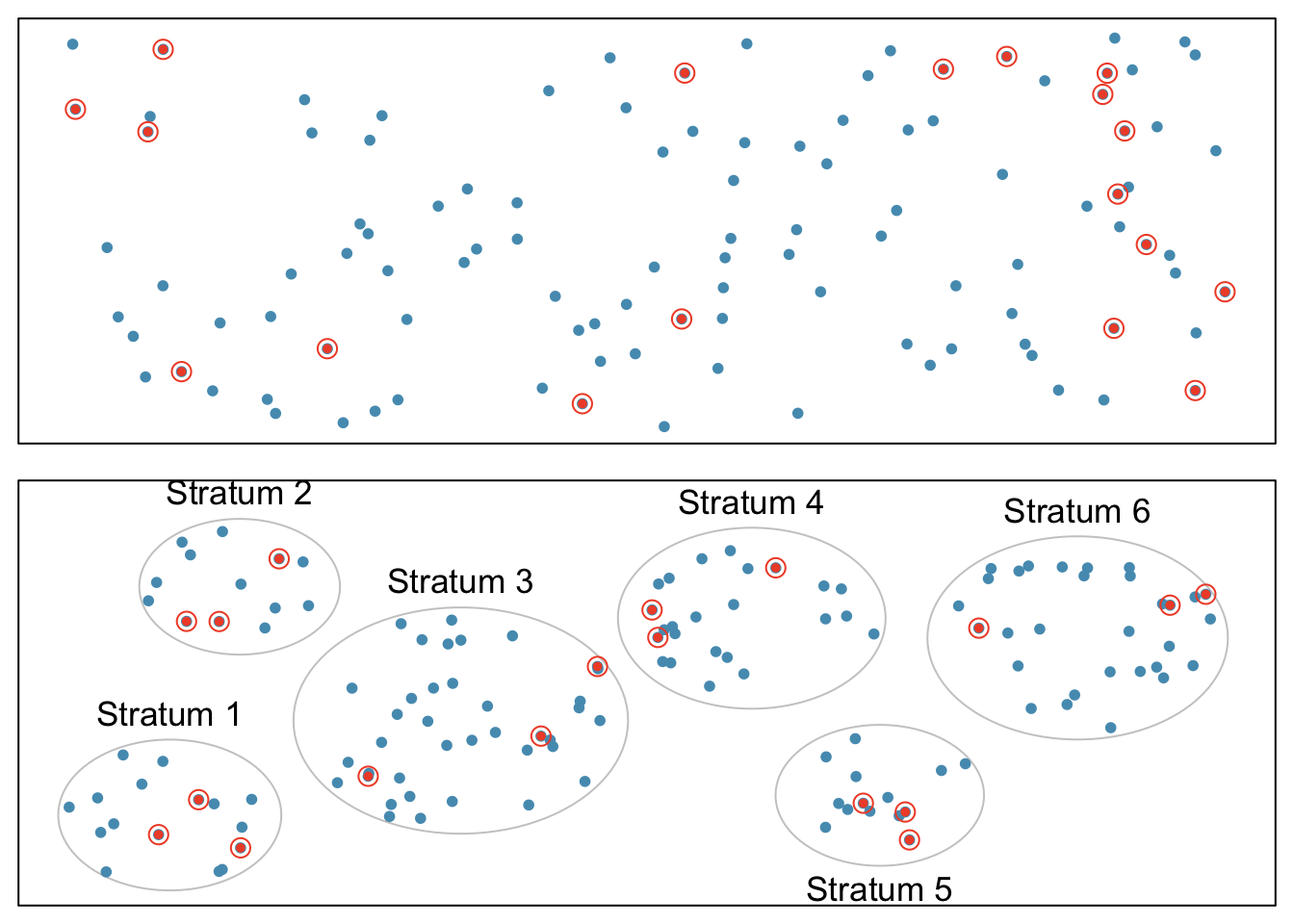
Figure 1.9: Examples of simple random and stratified sampling. In the top panel, simple random sampling is used to randomly select 18 cases (circled orange dots) out of the total population (all dots). The bottom panel illustrates stratified sampling: cases are grouped into six strata, then simple random sampling is employed within each stratum.
In a cluster sample, the population is first divided into many groups, called clusters. Then, a fixed number of clusters is sampled and all observations from each of those clusters are included in the sample (Figure 1.10, top panel). A multistage sample is similar to a cluster sample, but rather than keeping all observations in each cluster, a random sample is collected within each selected cluster (Figure 1.10, bottom panel).
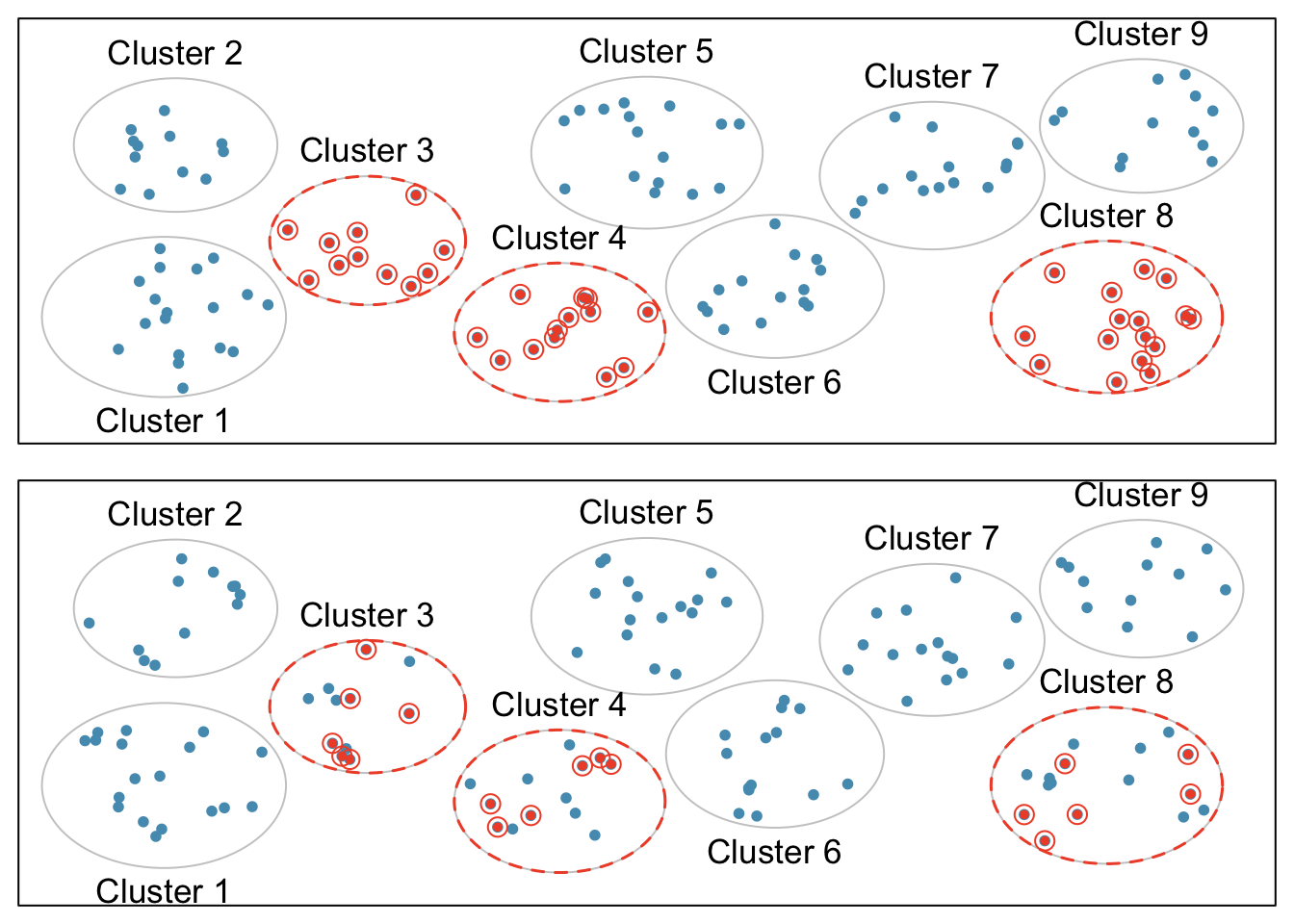
Figure 1.10: Examples of cluster cluster sampling and multistage sampling. The top panel illustrates cluster sampling: data are binned into nine clusters, three of which are sampled, and all observations within these clusters are sampled. The bottom panel illustrates multistage sampling, which differs from cluster sampling in that only a subset from each of the three selected clusters are sampled.
Unlike with stratified sampling, cluster and multistage sampling are most helpful when there is high case-to-case variability within a cluster, but the clusters themselves are similar to one another. For example, if neighborhoods in a city represent clusters, cluster and multistage sampling work best when the population within each neighborhood is very diverse, but neighborhoods are relatively similar.
Applying stratified, cluster, or multistage sampling can often be more economical than only drawing random samples. However, analysis of data collected using such methods is more complicated than when using data from a simple random sample; this text will only discuss analysis methods for simple random samples.
1.3.5 Introducing experiments and observational studies
The two primary types of study designs used to collect data are experiments and observational studies.
In an experiment, researchers directly influence how data arise, such as by assigning groups of individuals to different treatments and assessing how the outcome varies across treatment groups. The LEAP study is an example of an experiment with two groups, an experimental group that received the intervention (peanut consumption) and a control group that received a standard approach (peanut avoidance). In studies assessing effectiveness of a new drug, individuals in the control group typically receive a placebo, an inert substance with the appearance of the experimental intervention. The study is designed such that on average, the only difference between the individuals in the treatment groups is whether or not they consumed peanut protein. This allows for observed differences in experimental outcome to be directly attributed to the intervention and constitute evidence of a causal relationship between intervention and outcome.
In an observational study, researchers merely observe and record data, without interfering with how the data arise. For example, to investigate why certain diseases develop, researchers might collect data by conducting surveys, reviewing medical records, or following a cohort of many similar individuals. Observational studies can provide evidence of an association between variables, but cannot by themselves show a causal connection. However, there are many instances where randomized experiments are unethical, such as to explore whether lead exposure in young children is associated with cognitive impairment.
1.3.6 Experiments
Experimental design is based on three principles: control, randomization, and replication.
Control: When selecting participants for a study, researchers work to control for extraneous variables and choose a sample of participants that is representative of the population of interest. For example, participation in a study might be restricted to individuals who have a condition that suggests they may benefit from the intervention being tested. Infants enrolled in the LEAP study were required to be between 4 and 11 months of age, with severe eczema and/or allergies to eggs.
Randomization: Randomly assigning patients to treatment groups ensures that groups are balanced with respect to both variables that can and cannot be controlled. For example, randomization in the LEAP study ensures that the proportion of males to females is approximately the same in both groups. Additionally, perhaps some infants were more susceptible to peanut allergy because of an undetected genetic condition; under randomization, it is reasonable to assume that such infants were present in equal numbers in both groups. Randomization allows differences in outcome between the groups to be reasonably attributed to the treatment rather than inherent variability in patient characteristics, since the treatment represents the only systematic difference between the two groups.
In situations where researchers suspect that variables other than the intervention may influence the response, individuals can be first grouped into blocks according to a certain attribute and then randomized to treatment group within each block; this technique is referred to as blocking or stratification. The team behind the LEAP study stratified infants into two cohorts based on whether or not the child developed a red, swollen mark (a wheal) after a skin test at the time of enrollment; afterwards, infants were randomized between peanut consumption and avoidance groups. Figure 1.11 illustrates the blocking scheme used in the study.
Replication: The results of a study conducted on a larger number of cases are generally more reliable than smaller studies; observations made from a large sample are more likely to be representative of the population of interest. In a single study, replication is accomplished by collecting a sufficiently large sample. The LEAP study randomized a total of 640 infants.
Randomized experiments are an essential tool in research. The US Food and Drug Administration typically requires that a new drug can only be marketed after two independently conducted randomized trials confirm its safety and efficacy; the European Medicines Agency has a similar policy. Large randomized experiments in medicine have provided the basis for major public health initiatives. In 1954, approximately 750,000 children participated in a randomized study comparing polio vaccine with a placebo.10 In the United States, the results of the study quickly led to the widespread and successful use of the vaccine for polio prevention.
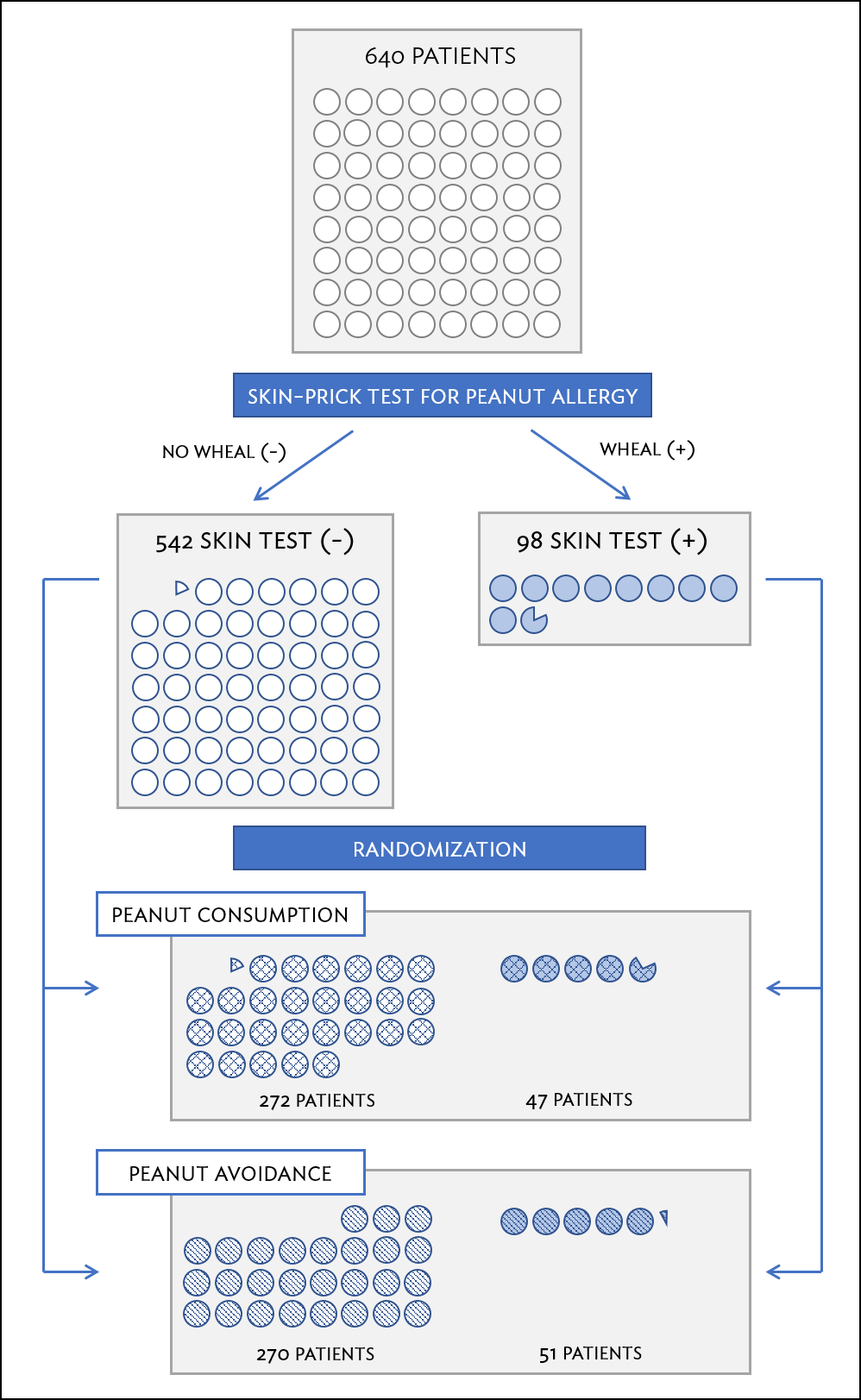
Figure 1.11: A simplified schematic of the blocking scheme used in the LEAP study, depicting 640 patients that underwent randomization. Patients are first divided into blocks based on response to the initial skin test, then each block is randomized between the avoidance and consumption groups. This strategy ensures an even representation of patients in each group who had positive and negative skin tests.
1.3.7 Observational studies
In observational studies, researchers simply observe selected potential explanatory and response variables. Participants who differ in important explanatory variables may also differ in other ways that influence response; as a result, it is not advisable to make causal conclusions about the relationship between explanatory and response variables based on observational data. For example, while observational studies of obesity have shown that obese individuals tend to die sooner than individuals with normal weight, it would be misleading to conclude that obesity causes shorter life expectancy. Instead, underlying factors are probably involved; obese individuals typically exhibit other health behaviors that influence life expectancy, such as reduced exercise or unhealthy diet.
Suppose that an observational study tracked sunscreen use and incidence of skin cancer, and found that the more sunscreen a person uses, the more likely they are to have skin cancer. These results do not mean that sunscreen causes skin cancer. One important piece of missing information is sun exposure – if someone is often exposed to sun, they are both more likely to use sunscreen and to contract skin cancer (Figure 1.12). Sun exposure is a confounding variable: a variable associated with both the explanatory and response variables (also called a lurking variable, confounding factor, or a confounder). There is no guarantee that all confounding variables can be examined or measured; as a result, it is not advisable to draw causal conclusions from observational studies.
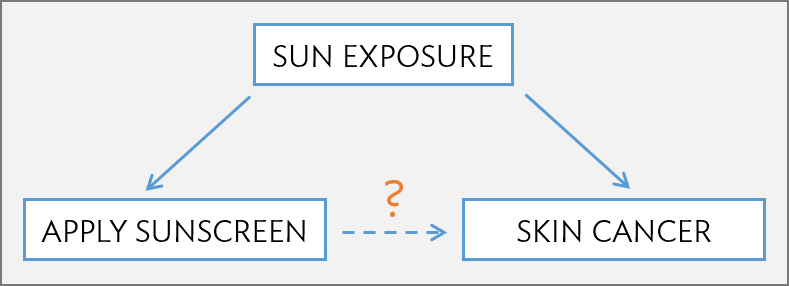
Figure 1.12: Confounding triangle example.
Confounding is not limited to observational studies. For example, consider a randomized study comparing two treatments (varenicline and buproprion) against a placebo as therapies for aiding smoking cessation.11 At the beginning of the study, participants were randomized into groups: 352 to varenicline, 329 to buproprion, and 344 to placebo. Not all participants successfully completed the assigned therapy: 259, 225, and 215 patients in each group did so, respectively. If an analysis were based only on the participants who completed therapy, this could introduce confounding; it is possible that there are underlying differences between individuals who complete the therapy and those who do not. Including all randomized participants in the final analysis maintains the original randomization scheme and controls for differences between the groups. This strategy, commonly used for analyzing clinical trial data, is referred to as an intention-to-treat analysis.
Observational studies may reveal interesting patterns or associations that can be further investigated with follow-up experiments. Several observational studies based on dietary data from different countries showed a strong association between dietary fat and breast cancer in women. These observations led to the launch of the Women’s Health Initiative (WHI), a large randomized trial sponsored by the US National Institutes of Health (NIH). In the WHI, women were randomized to standard versus low fat diets, and the previously observed association was not confirmed.
Observational studies can be either prospective or retrospective. A prospective study identifies participants and collects information at scheduled times or as events unfold. For example, in the Nurses’ Health Study, researchers recruited registered nurses beginning in 1976 and collected data through administering biennial surveys; data from the study have been used to investigate risk factors for major chronic diseases in women. Retrospective studies collect data after events have taken place, such as from medical records. Some datasets may contain both retrospectively- and prospectively-collected variables. The Cancer Care Outcomes Research and Surveillance Consortium (CanCORS) enrolled participants with lung or colorectal cancer, collected information about diagnosis, treatment, and previous health behavior, but also maintained contact with participants to gather data about long-term outcomes.12
1.4 Numerical data
This section discusses techniques for exploring and summarizing numerical variables, using the frog data from the parental investment study introduced in Section 1.2.
1.4.1 Measures of center: mean and median
The mean, sometimes called the average, is a measure of center for a distribution of data. To find the average clutch volume for the observed egg clutches, add all the clutch volumes and divide by the total number of clutches. For computational convenience, the volumes are rounded to the first~decimal.
\[
\overline{y} = \frac{177.8 + 257.0 + \cdots + 933.3}{431} = 882.5\ \textrm{mm}^{3}.
\]
The sample mean is often labeled \(\overline{y}\), to distinguish it from \(\mu\), the mean of the entire population from which the sample is drawn. The letter \(y\) is being used as a generic placeholder for the variable of interest, clutch.volume.
Definition 1.1 (Mean) The sample mean of a numerical variable is the sum of the values of all observations divided by the number of observations: \[\overline{y} = \frac{y_1+y_2+\cdots+y_n}{n},\] where \(y_1, y_2, \dots, y_n\) represent the \(n\) observed values.
The median is another measure of center; it is the middle number in a distribution after the values have been ordered from smallest to largest. If the distribution contains an even number of observations, the median is the average of the middle two observations. There are 431 clutches in the dataset, so the median is the clutch volume of the \(216^{th}\) observation in the sorted values of clutch.volume: \(831.8\ \textrm{mm}^{3}\).
1.4.2 Measures of spread: standard deviation and interquartile range
The spread of a distribution refers to how similar or varied the values in the distribution are to each other; i.e., whether the values are tightly clustered or spread over a wide range.
The standard deviation for a set of data describes the typical distance between an observation and the mean. The distance of a single observation from the mean is its deviation. Below are the deviations for the \(1^{st}\), \(2^{nd}\), \(3^{rd}\), and \(431^{st}\) observations in the clutch.volume variable.
\[\begin{align*} y_1-\overline{y} &= 177.8 - 882.5 = -704.7 \hspace{5mm}\text{ } \\ y_2-\overline{y} &= 257.0 - 882.5 = -625.5 \\ y_3-\overline{y} &= 151.4 - 882.5 = -731.1 \\ &\ \vdots \\ y_{431}-\overline{y} &= 933.2 - 882.5 = 50.7 \end{align*}\]
The sample variance, the average of the squares of these deviations, is denoted by \(s^2\):
\[\begin{align*} s^2 &= \frac{(-704.7)^2 + (-625.5)^2 + (-731.1)^2 + \cdots + (50.7)^2}{431-1} \\ &= \frac{496,602.09 + 391,250.25 + 534,507.21 + \cdots + 2570.49}{430} \\ &= 143,680.9. \end{align*}\]
The denominator is \(n-1\) rather than \(n\); this mathematical nuance accounts for the fact that sample mean has been used to estimate the population mean in the calculation. Details on the statistical theory can be found in more advanced texts.
The sample standard deviation \(s\) is the square root of the variance: \[s=\sqrt{143,680.9} = 379.05 \textrm{mm}^{3}.\]
Like the mean, the population values for variance and standard deviation are denoted by Greek letters: \(\sigma_{}^2\) for the variance and \(\sigma\) for the standard deviation.
Definition 1.2 (Standard Deviation) The sample standard deviation of a numerical variable is computed as the square root of the variance, which is the sum of squared deviations divided by the number of observations minus 1. \[\begin{eqnarray} s = \sqrt{\frac{({y_1 - \overline{y})}^{2}+({y_2 - \overline{y})}^{2}+\cdots+({y_n - \overline{y})}^{2}}{n-1}}, \label{SDEquation} \end{eqnarray}\] where \(y_1, y_2, \dots, y_n\) represent the \(n\) observed values.
Variability can also be measured using the interquartile range (IQR). The IQR for a distribution is the difference between the first and third quartiles: \(Q_3 - Q_1\). The first quartile (\(Q_1\)) is equivalent to the 25\(^{th}\) percentile; i.e., 25% of the data fall below this value. The third quartile (\(Q_3\)) is equivalent to the 75\(^{th}\) percentile. By definition, the median represents the second quartile, with half the values falling below it and half falling above. The IQR for clutch.volume is \(1096.0 - 609.6 = 486.4\ \textrm{mm}^{3}\).
Measures of center and spread are ways to summarize a distribution numerically. Using numerical summaries allows for a distribution to be efficiently described with only a few numbers. Numerical summaries are also known as summary statistics. For example, the calculations for clutch.volume indicate that the typical egg clutch has volume of about 880 mm\(^3\), while the middle \(50\%\) of egg clutches have volumes between approximately \(600\ \textrm{mm}^{3}\) and \(1100.0\ \textrm{mm}^{3}\).
1.4.3 Robust estimates
Figure 1.13 shows the values of clutch.volume as points on a single axis. There are a few values that seem extreme relative to the other observations: the four largest values, which appear distinct from the rest of the distribution. How do these extreme values affect the value of the numerical summaries?
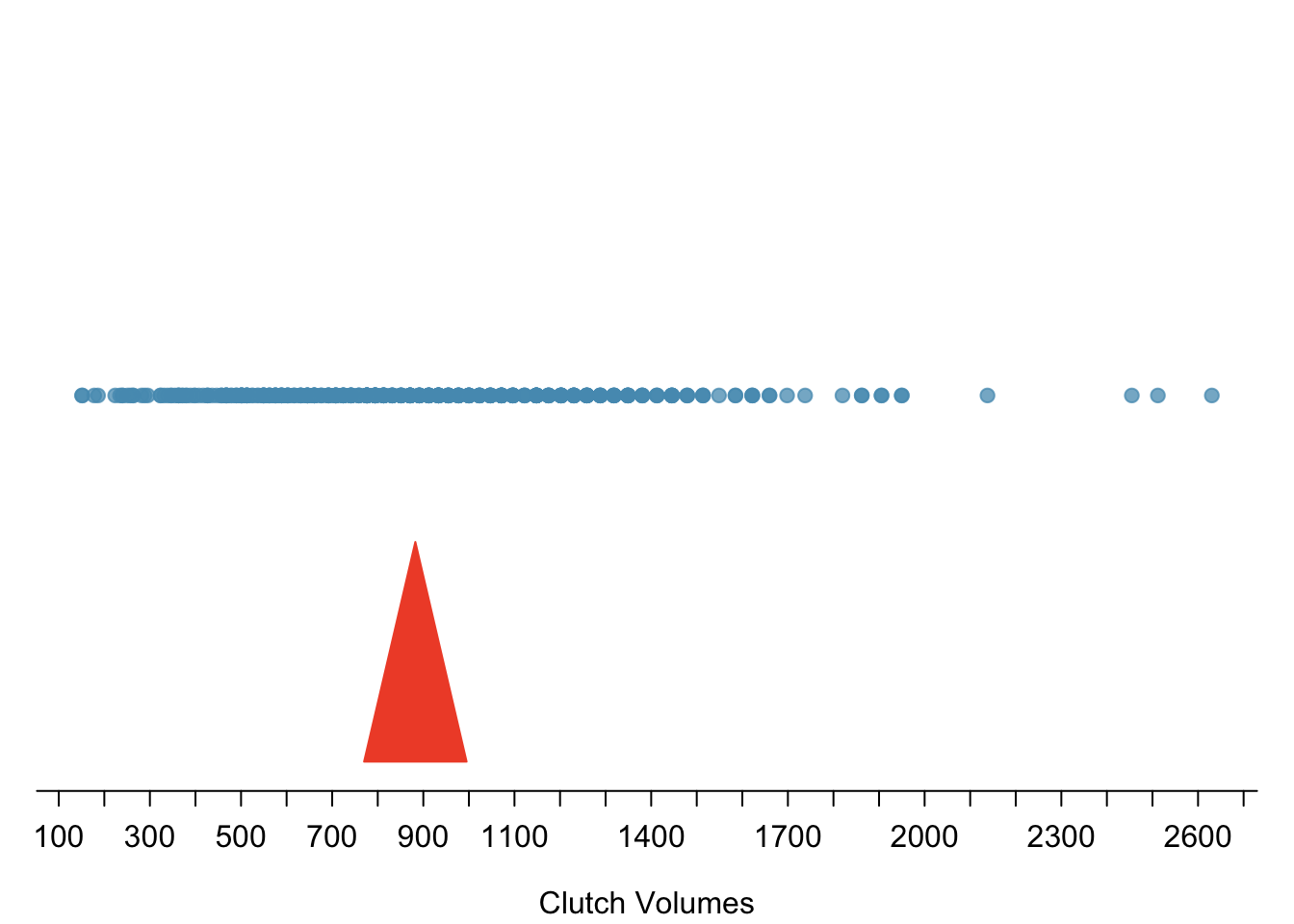
Figure 1.13: Dot plot of clutch volumes from the frog from the oibiostat package data.
Figure 1.14 shows the summary statistics calculated under two scenarios, one with and one without the four largest observations. For these data, the median does not change, while the IQR differs by only about 6 \(\textrm{mm}^{3}\). In contrast, the mean and standard deviation are much more affected, particularly the standard deviation.

Figure 1.14: A comparison of how the median, IQR, mean (\(\overline{y}\)), and standard deviation (\(s\)) change when extreme observations are present.
The median and IQR are referred to as robust estimates because extreme observations have little effect on their values. For distributions that contain extreme values, the median and IQR will provide a more accurate sense of the center and spread than the mean and standard deviation.
1.4.4 Visualizing distributions of data: histograms and boxplots
Graphs show important features of a distribution that are not evident from numerical summaries, such as asymmetry or extreme values. While dot plots show the exact value of each observation, histograms and boxplots graphically summarize distributions.
In a histogram, observations are grouped into bins and plotted as bars. Figure 1.15 shows the number of clutches with volume between 0 and 200 \(\textrm{mm}^{3}\), 200 and 400 \(\textrm{mm}^{3}\), etc. up until 2,600 and 2,800 \(\textrm{mm}^{3}\). Note: By default in R, the bins are left-open and right-closed; i.e., the intervals are of the form (a, b]. Thus, an observation with value 200 would fall into the 0-200 bin instead of the 200-400 bin.} These binned counts are plotted in Figure 1.16.

Figure 1.15: The counts for the binned ar{clutch.volume} data.
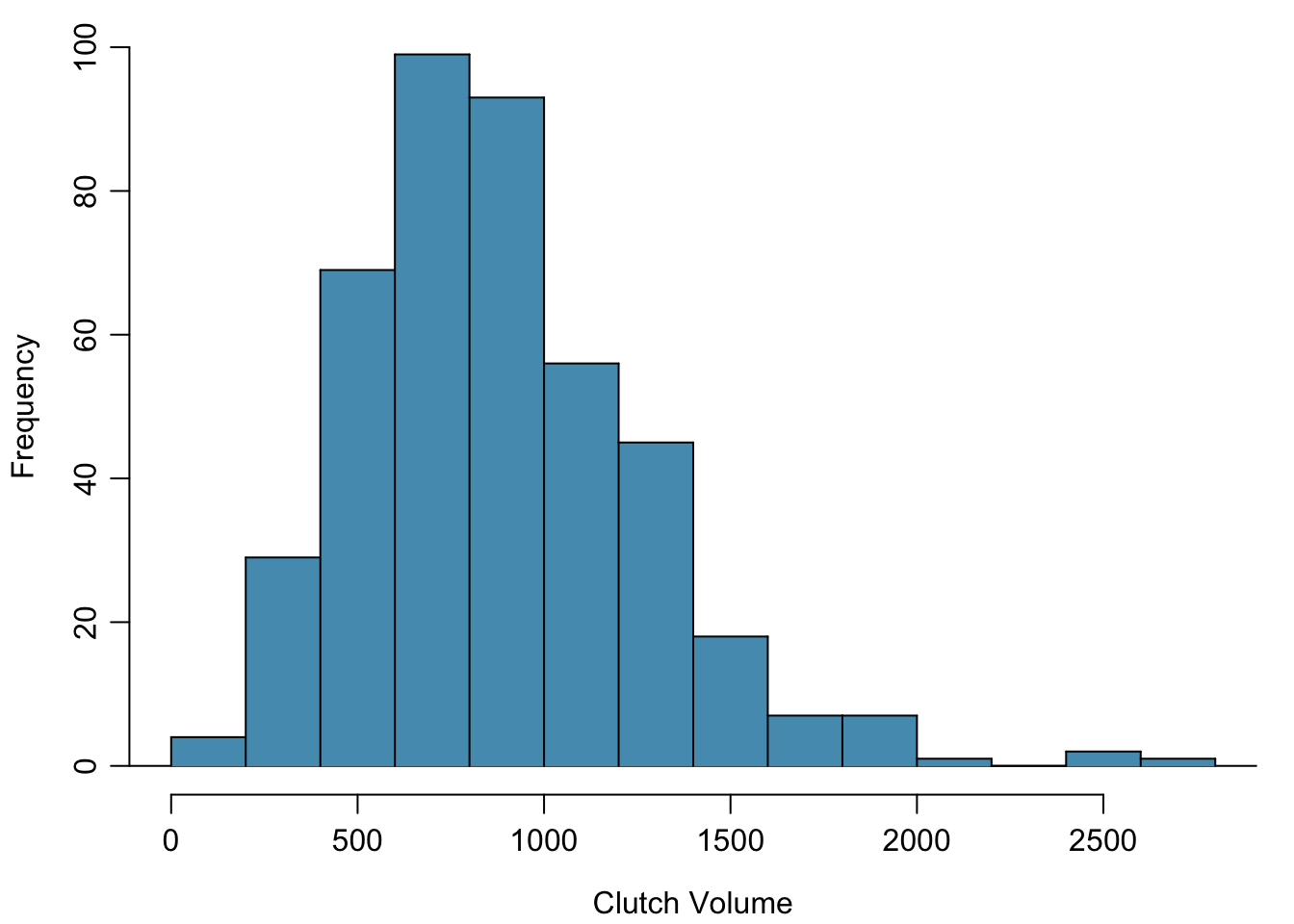
Figure 1.16: A histogram of clutch.volume.
Histograms provide a view of the data density. Higher bars indicate more frequent observations, while lower bars represent relatively rare observations. Figure 1.16 shows that most of the egg clutches have volumes between 500-1,000 mm\(^3\), and there are many more clutches with volumes smaller than 1,000 mm\(^{3}\) than clutches with larger volumes.
Histograms show the shape of a distribution. The tails of a symmetric distribution are roughly equal, with data trailing off from the center roughly equally in both directions. Asymmetry arises when one tail of the distribution is longer than the other. A distribution is said to be right skewed when data trail off to the right, and left skewed when data trail off to the left. Other ways to describe data that are skewed to the right/left: skewed to the right/left or skewed to the positive/negative end. Figure 1.16 shows that the distribution of clutch volume is right skewed; most clutches have relatively small volumes, and only a few clutches have high volumes.
A mode is represented by a prominent peak in the distribution. Another definition of mode, which is not typically used in statistics, is the value with the most occurrences. It is common that a dataset contains no observations with the same value, which makes this other definition impractical for many datasets. Figure 1.17 shows histograms that have one, two, or three major peaks. Such distributions are called unimodal, bimodal, and multimodal, respectively. Any distribution with more than two prominent peaks is called multimodal. Note that the less prominent peak in the unimodal distribution was not counted since it only differs from its neighboring bins by a few observations. Prominent is a subjective term, but it is usually clear in a histogram where the major peaks are.
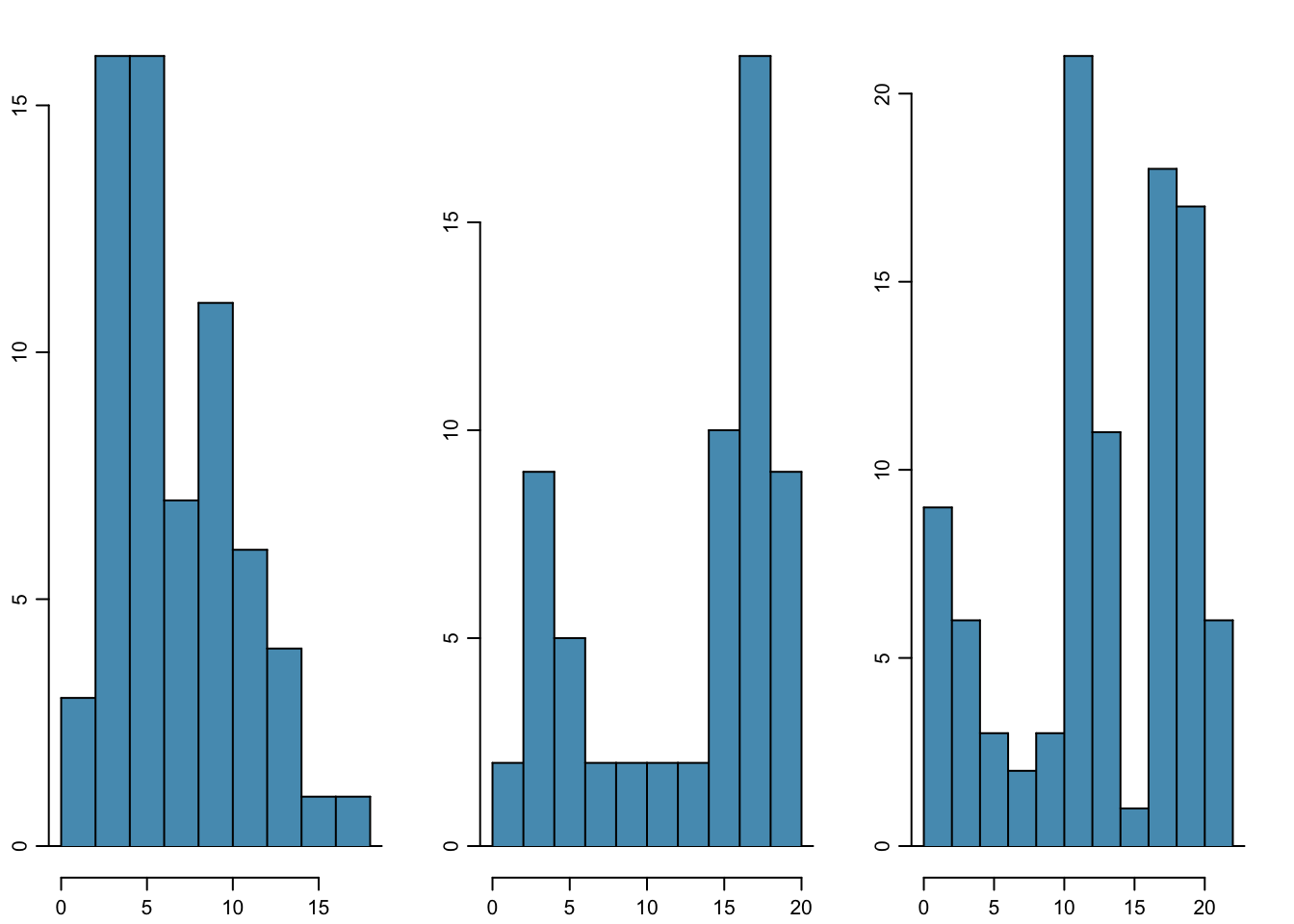
Figure 1.17: From left to right: unimodal, bimodal, and multimodal distributions.
A boxplot indicates the positions of the first, second, and third quartiles of a distribution in addition to extreme observations. Boxplots are also known as box-and-whisker plots. Figure 1.18 shows a boxplot of clutch.volume alongside a vertical dot plot.
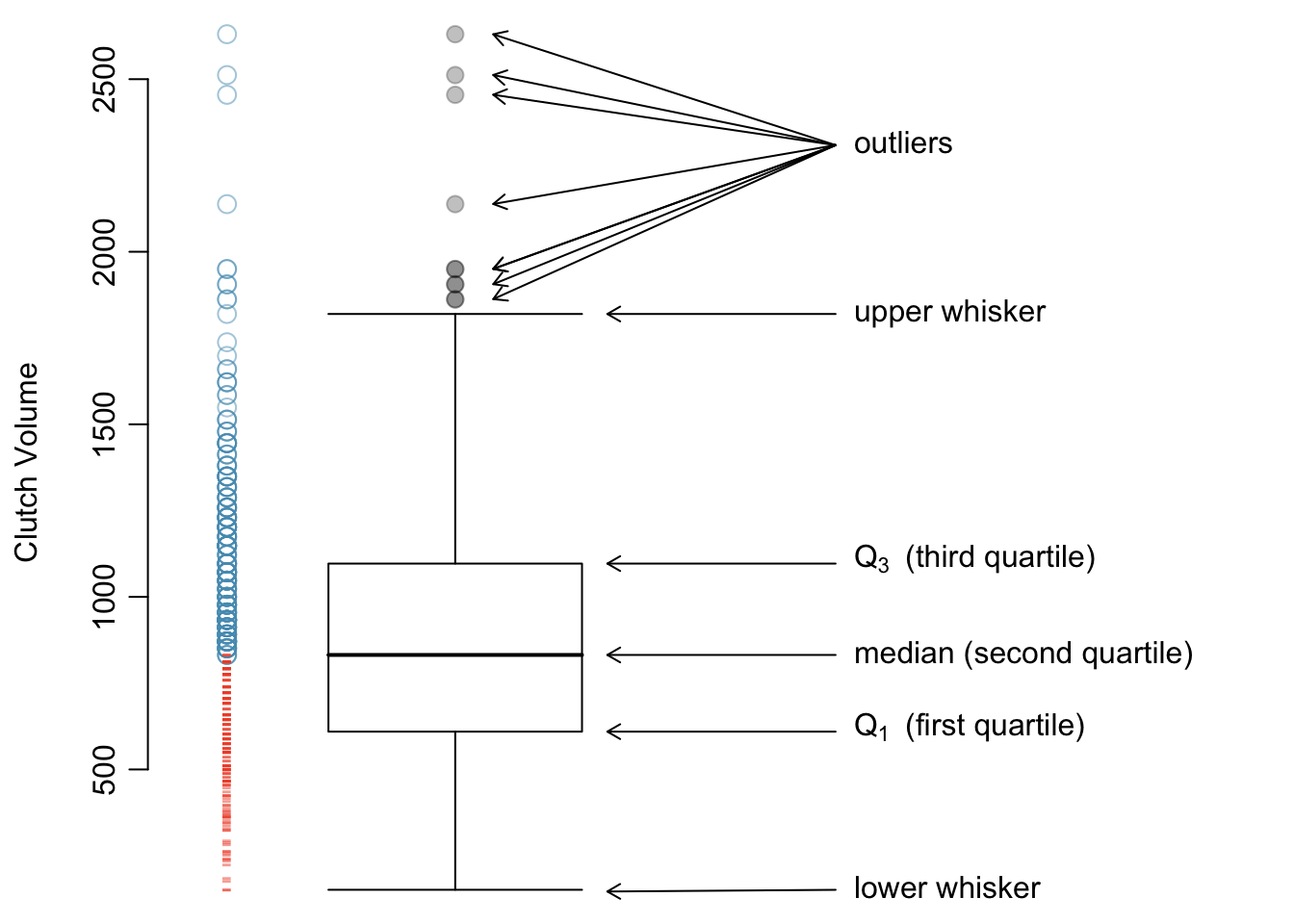
Figure 1.18: A boxplot and dot plot of clutch.volume. The horizontal dashes indicate the bottom 50% of the data and the open circles represent the top 50%.
In a boxplot, the interquartile range is represented by a rectangle extending from the first quartile to the third quartile, and the rectangle is split by the median (second quartile). Extending outwards from the box, the whiskers capture the data that fall between \(Q_1 - 1.5\times IQR\) and \(Q_3 + 1.5\times IQR\). The whiskers must end at data points; the values given by adding or subtracting \(1.5\times IQR\) define the maximum reach of the whiskers. For example, with the clutch.volume variable, \(Q_3 + 1.5 \times IQR = 1,096.5 + 1.5\times 486.4 = 1,826.1\ \textrm {mm}^{3}\). However, there was no clutch with volume 1,826.1 \(\textrm {mm}^{3}\); thus, the upper whisker extends to 1,819.7 \(\textrm {mm}^{3}\), the largest observation that is smaller than \(Q_3 + 1.5\times IQR\).
Any observation that lies beyond the whiskers is shown with a dot; these observations are called outliers. An outlier is a value that appears extreme relative to the rest of the data. For the clutch.volume variable, there are several large outliers and no small outliers, indicating the presence of some unusually large egg clutches.
The high outliers in Figure 1.18 reflect the right-skewed nature of the data. The right skew is also observable from the position of the median relative to the first and third quartiles; the median is slightly closer to the first quartile. In a symmetric distribution, the median will be halfway between the first and third quartiles.
1.4.5 Transforming data
When working with strongly skewed data, it can be useful to apply a transformation, and rescale the data using a function. A natural log transformation is commonly used to clarify the features of a variable when there are many values clustered near zero and all observations are positive.
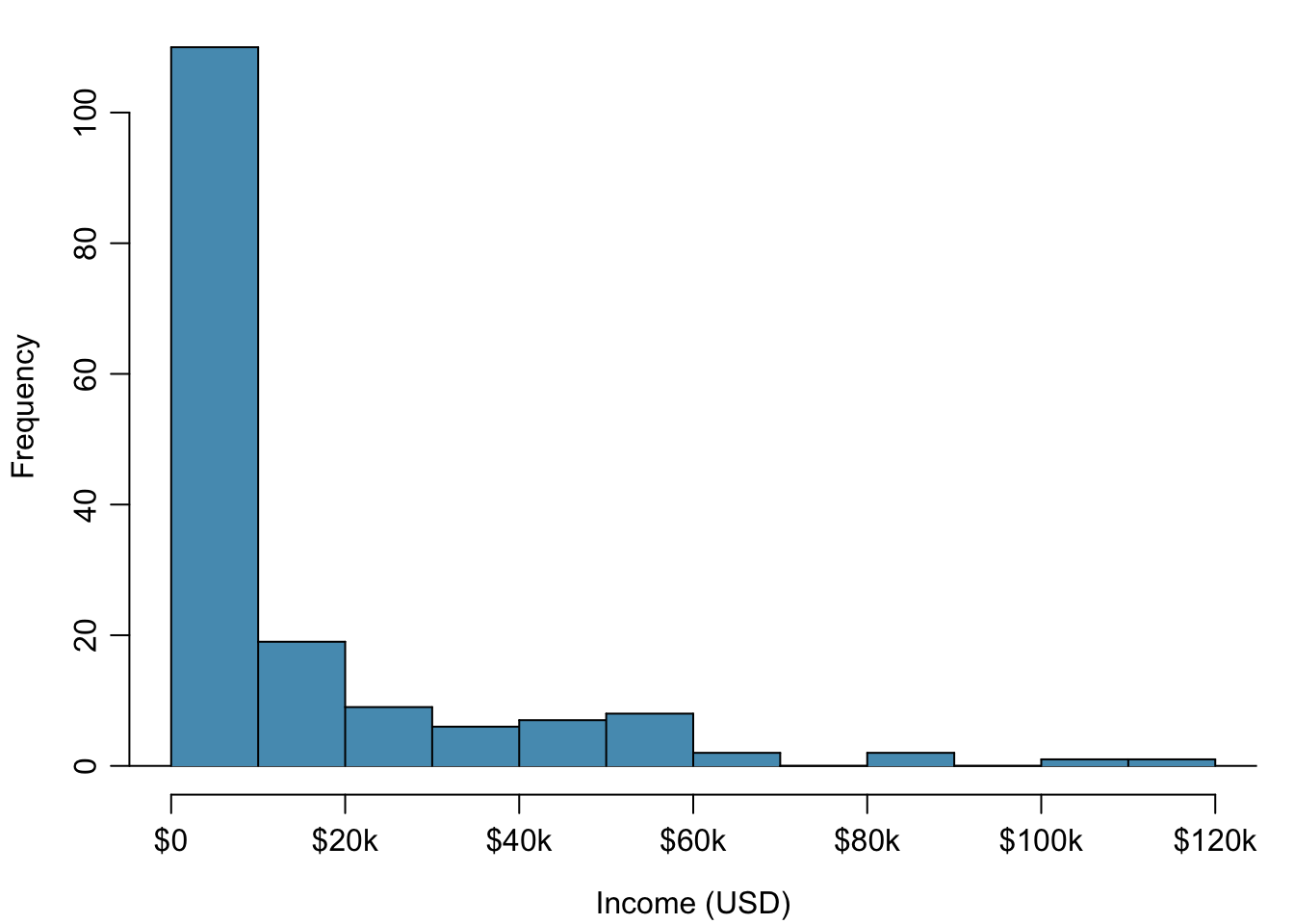
Figure 1.19: Histogram of per capita income.
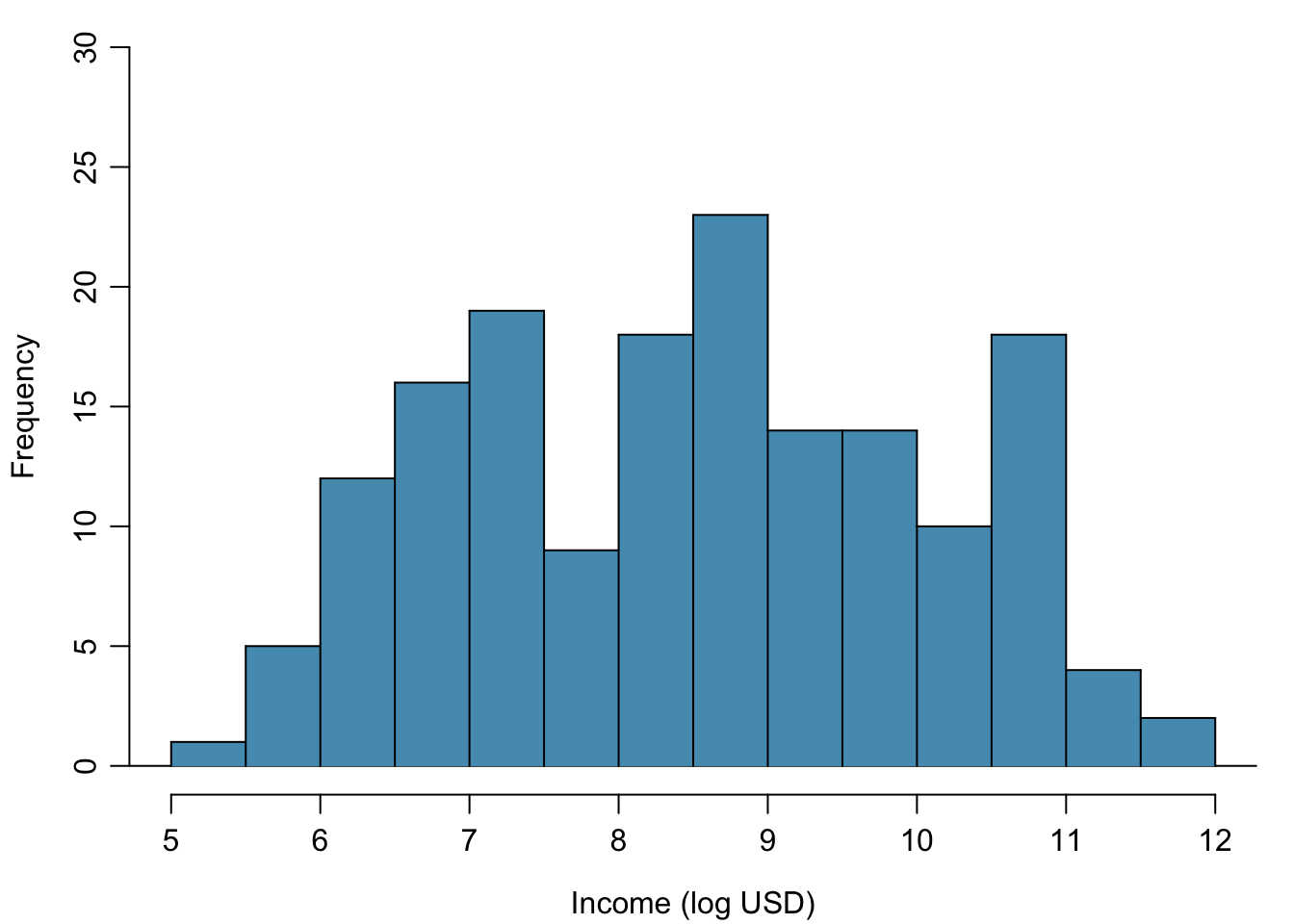
Figure 1.20: Histogram of the log-transformed per capita income.
For example, income data are often skewed right; there are typically large clusters of low to moderate income, with a few large incomes that are outliers. Figure 1.19 shows a histogram of average yearly per capita income measured in US dollars for 165 countries in 2011. The data are available as wdi.2011 in the R package oibiostat. The data are heavily right skewed, with the majority of countries having average yearly per capita income lower than $10,000. Once the data are log-transformed, the distribution becomes roughly symmetric (Figure 1.20). In statistics, the natural logarithm is usually written \(\log\). In other settings it is sometimes written as \(\ln\).
For symmetric distributions, the mean and standard deviation are particularly informative summaries. If a distribution is symmetric, approximately 70% of the data are within one standard deviation of the mean and 95% of the data are within two standard deviations of the mean; this guideline is known as the empirical rule.
Example 1.1 On the log-transformed scale, mean \(\log\) income is 8.50, with standard deviation 1.54. Apply the empirical rule to describe the distribution of average yearly per capita income among the 165 countries.
According to the empirical rule, the middle 70% of the data are within one standard deviation of the mean, in the range (8.50 - 1.54, 8.50 + 1.54) = (6.96, 10.04) log(USD). 95% of the data are within two standard deviations of the mean, in the range (8.50 - 2(1.54), 8.50 + 2(1.54)) = (5.42, 11.58) log(USD).
Undo the log transformation. The middle 70% of the data are within the range \[ (e^{6.96}, e^{10.04}) = (1054, 22925)\]. The middle 95% of the data are within the range \[(e^{5.42}, e^{11.58}) = (226, 106937).\]
Functions other than the natural log can also be used to transform data, such as the square root and inverse.
1.5 Categorical data
This section introduces tables and plots for summarizing categorical data, using the famuss dataset from the oibiostat package.
A table for a single variable is called a frequency table. Table 1.2 is a frequency table for the variable, showing the distribution of genotype at location r577x on the ACTN3 gene for the FAMuSS study participants.
In a relative frequency table like Table @ref(tab:famussRelFrequencyTable}, the proportions per each category are shown instead of the counts.
| CC | CT | TT | Sum | |
|---|---|---|---|---|
| Counts | 173 | 261 | 161 | 595 |
| CC | CT | TT | Sum | |
|---|---|---|---|---|
| Proportions | 0.291 | 0.439 | 0.271 | 1 |
A bar plot is a common way to display a single categorical variable. The left panel of Figure 1.21 shows a bar plot of the counts per genotype for the actn3.r577x variable. The plot in the right panel shows the proportion of observations that are in each level (i.e. in each genotype).
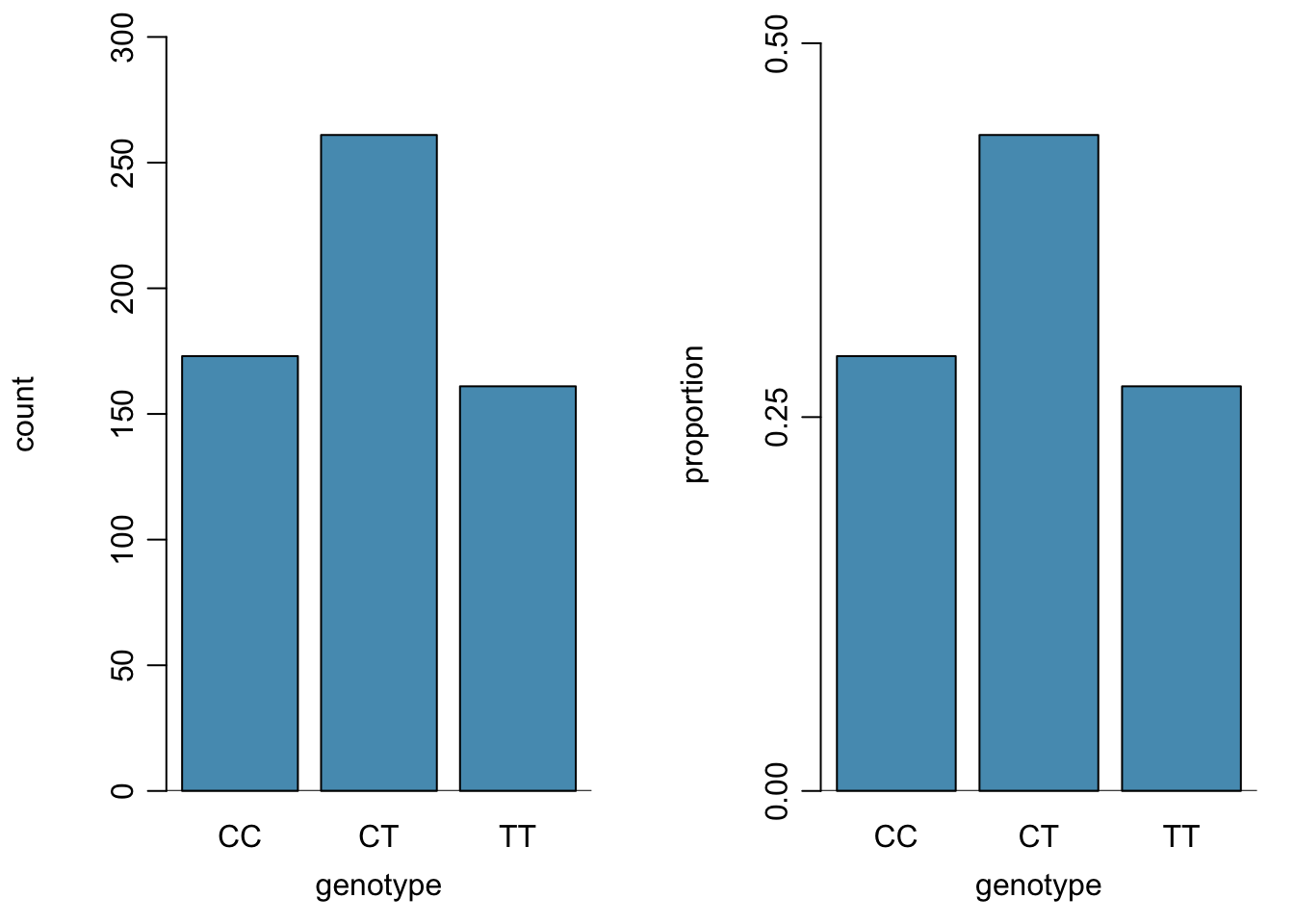
Figure 1.21: Two bar plots of actn3.r577x. The left panel shows the counts, and the right panel shows the proportions for each genotype.
1.6 Relationships between two variables
This section introduces numerical and graphical methods for exploring and summarizing relationships between two variables. Approaches vary depending on whether the two variables are both numerical, both categorical, or whether one is numerical and one is categorical.
1.6.1 Two numerical variables
1.6.1.1 Scatterplots
In the frog parental investment study, researchers used clutch volume as a primary variable of interest rather than egg size because clutch volume represents both the eggs and the protective gelatinous matrix surrounding the eggs. The larger the clutch volume, the higher the energy required to produce it; thus, higher clutch volume is indicative of increased maternal investment. Previous research has reported that larger body size allows females to produce larger clutches; is this idea supported by the frog data?
A scatterplot provides a case-by-case view of the relationship between two numerical variables. Figure 1.22 shows clutch volume plotted against body size, with clutch volume on the \(y\)-axis and body size on the \(x\)-axis. Each point represents a single case. For this example, each case is one egg clutch for which both volume and body size (of the female that produced the clutch) have been recorded.
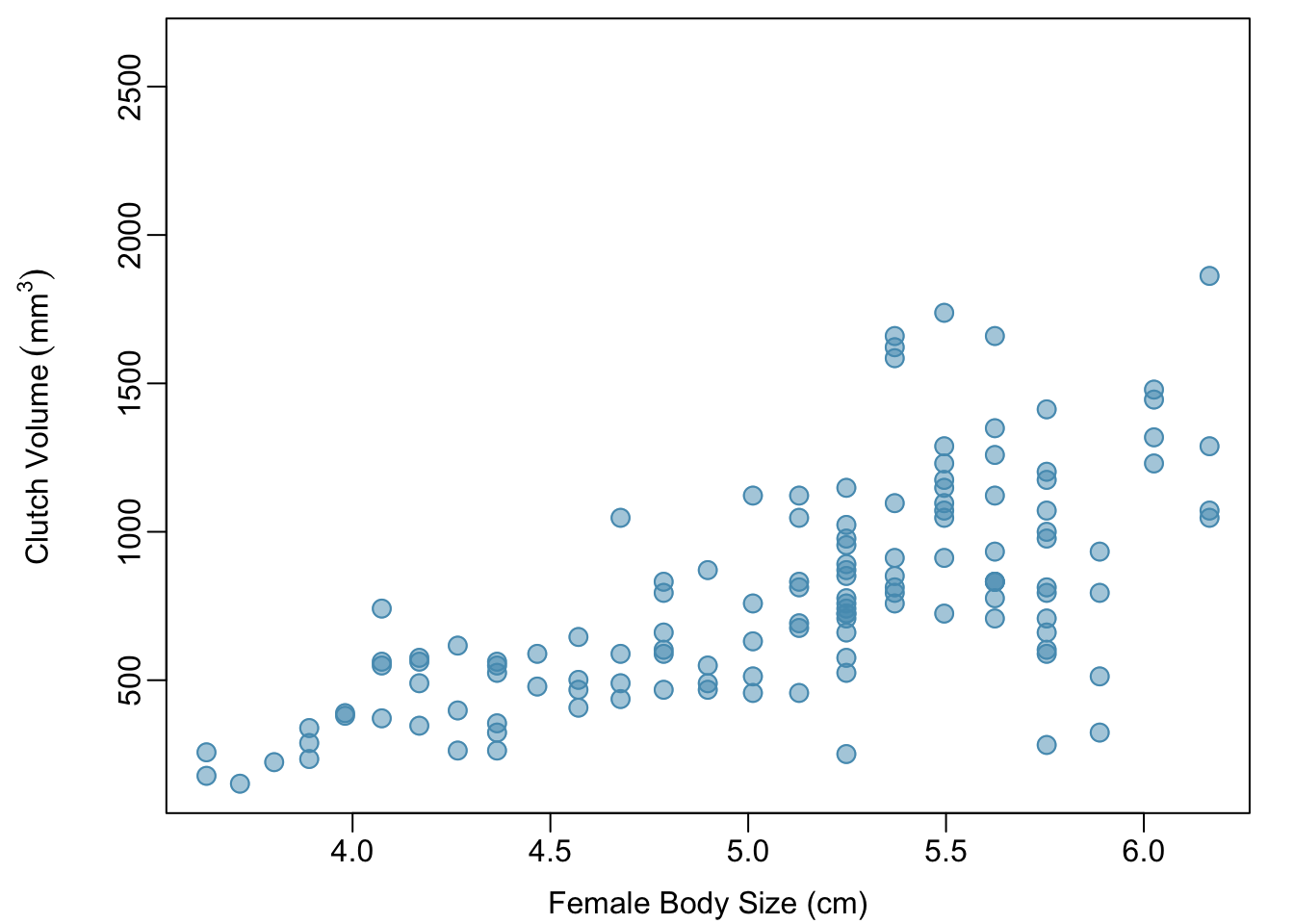
Figure 1.22: A scatterplot showing clutch.volume (vertical axis) vs. body.size (horizontal axis).
The plot shows a discernible pattern, which suggests an association, or relationship, between clutch volume and body size; the points tend to lie in a straight line, which is indicative of a linear association. Two variables are positively associated if increasing values of one tend to occur with increasing values of the other; two variables are negatively associated if increasing values of one variable occurs with decreasing values of the other. If there is no evident relationship between two variables, they are said to be uncorrelated or independent.
As expected, clutch volume and body size are positively associated; larger frogs tend to produce egg clutches with larger volumes. These observations suggest that larger females are capable of investing more energy into offspring production relative to smaller females.
The National Health and Nutrition Examination Survey (NHANES) consists of a set of surveys and measurements conducted by the US CDC to assess the health and nutritional status of adults and children in the United States. The following example uses data from a sample of 500 adults (individuals ages 21 and older) from the NHANES dataset. The sample is available as nhanes.samp.adult.500 in the oibiostat package.
Example 1.2 Body mass index (BMI) is a measure of weight commonly used by health agencies to assess whether someone is overweight, and is calculated from height and weight. Describe the relationships shown in Figures 1.23 and 1.24. Why is it helpful to use BMI as a measure of obesity, rather than weight? \[BMI = \dfrac{weight_{kg}}{height^{2}_m} = \dfrac{weight_{lb}}{height^{2}_{in}} \times 703\]
Figure 1.23 shows a positive association between height and weight; taller individuals tend to be heavier. Figure 1.24 shows that height and BMI do not seem to be associated; the range of BMI values observed is roughly consistent across height.
Weight itself is not a good measure of whether someone is overweight; instead, it is more reasonable to consider whether someone’s weight is unusual relative to other individuals of a comparable height. An individual weighing 200 pounds who is 6 ft tall is not necessarily an unhealthy weight; however, someone who weighs 200 pounds and is 5 ft tall is likely overweight. It is not reasonable to classify individuals as overweight or obese based only on weight.
BMI acts as a relative measure of weight that accounts for height. Specifically, BMI is used as an estimate of body fat. According to US National Institutes of Health (US NIH) and the World Health Organization (WHO), a BMI between 25.0 - 29.9 is considered overweight and a BMI over 30 is considered obese.
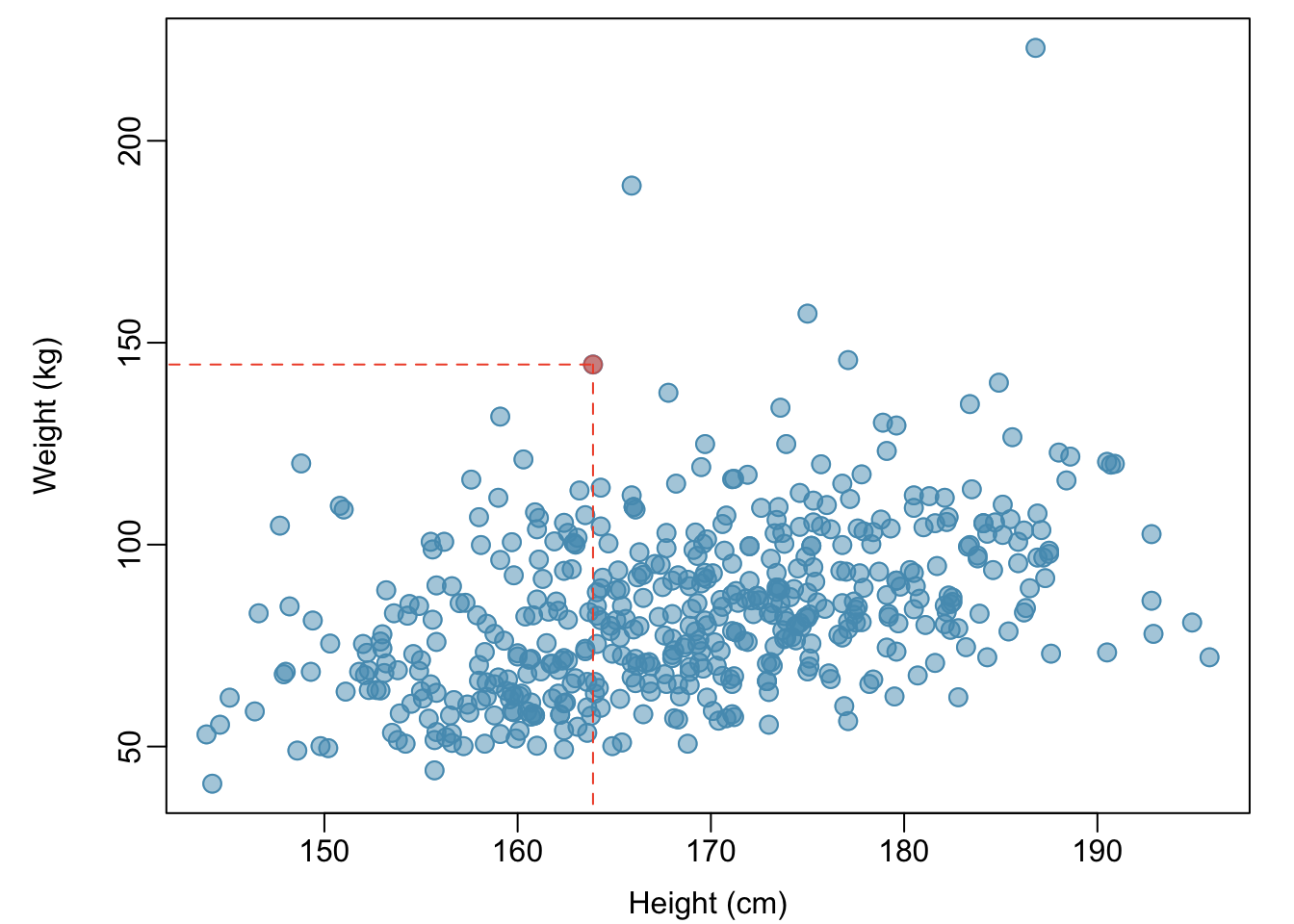
Figure 1.23: A scatterplot showing height versus weight from the 500 individuals in the sample from NHANES. One participant 163.9 cm tall (about 5 ft, 4 in) and weighing 144.6 kg (about 319 lb) is highlighted.
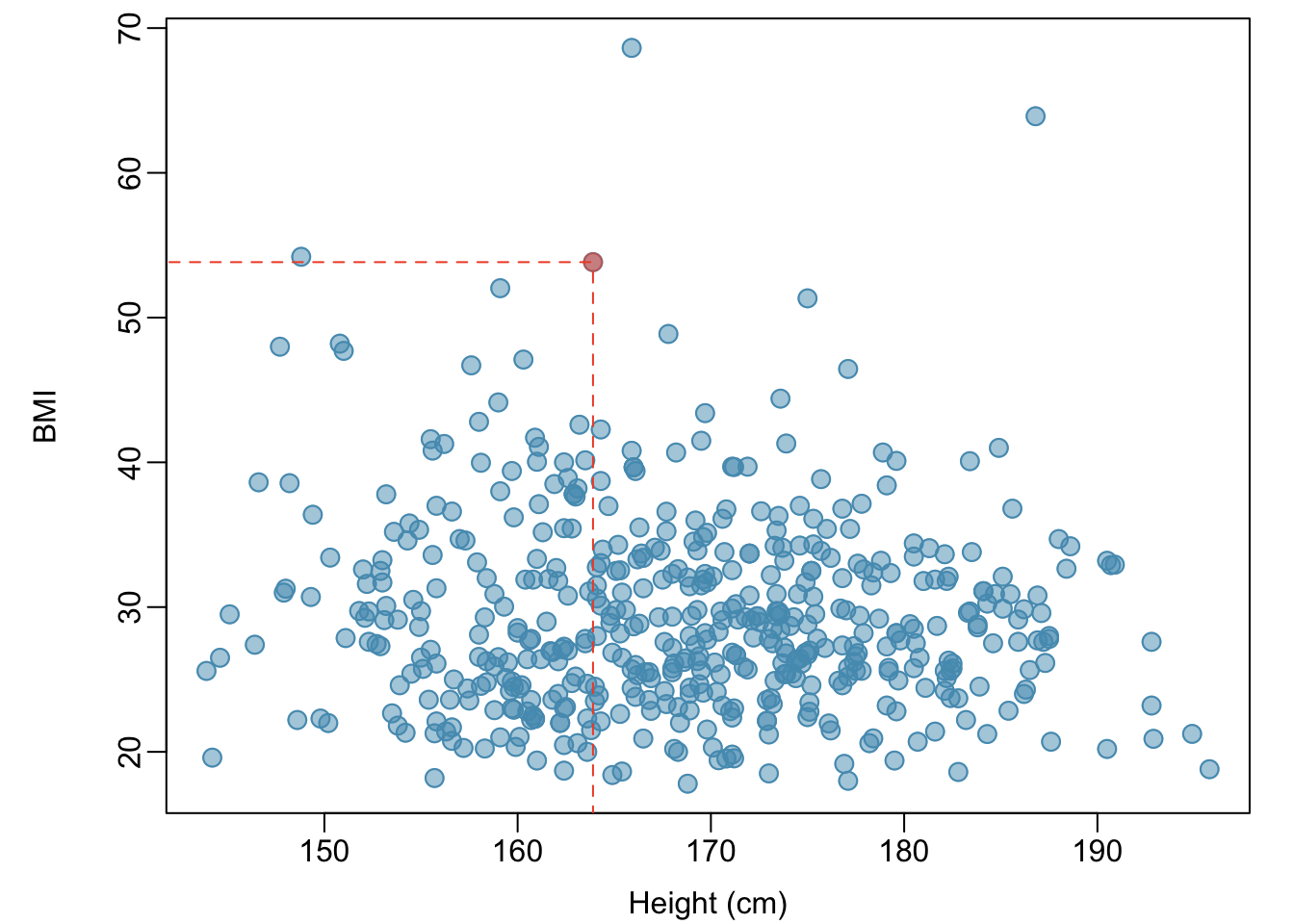
Figure 1.24: A scatterplot showing height versus BMI from the 500 individuals in the sample from NHANES. The same individual highlighted in Figure 1.23 is marked here, with BMI 53.83.
Example 1.3 Figure 1.25 is a scatterplot of life expectancy versus annual per capita income for 165 countries in 2011. Life expectancy is measured as the expected lifespan for children born in 2011 and income is adjusted for purchasing power in a country. Describe the relationship between life expectancy and annual per capita income; do they seem to be linearly associated?
Life expectancy and annual per capita income are positively associated; higher per capita income is associated with longer life expectancy. However, the two variables are not linearly associated. When income is low, small increases in per capita income are associated with relatively large increases in life expectancy. However, once per capita income exceeds approximately $20,000 per year, increases in income are associated with smaller gains in life expectancy.
In a linear association, change in the \(y\)-variable for every unit of the \(x\)-variable is consistent across the range of the \(x\)-variable; for example, a linear association would be present if an increase in income of $10,000 corresponded to an increase in life expectancy of 5 years, across the range of income.
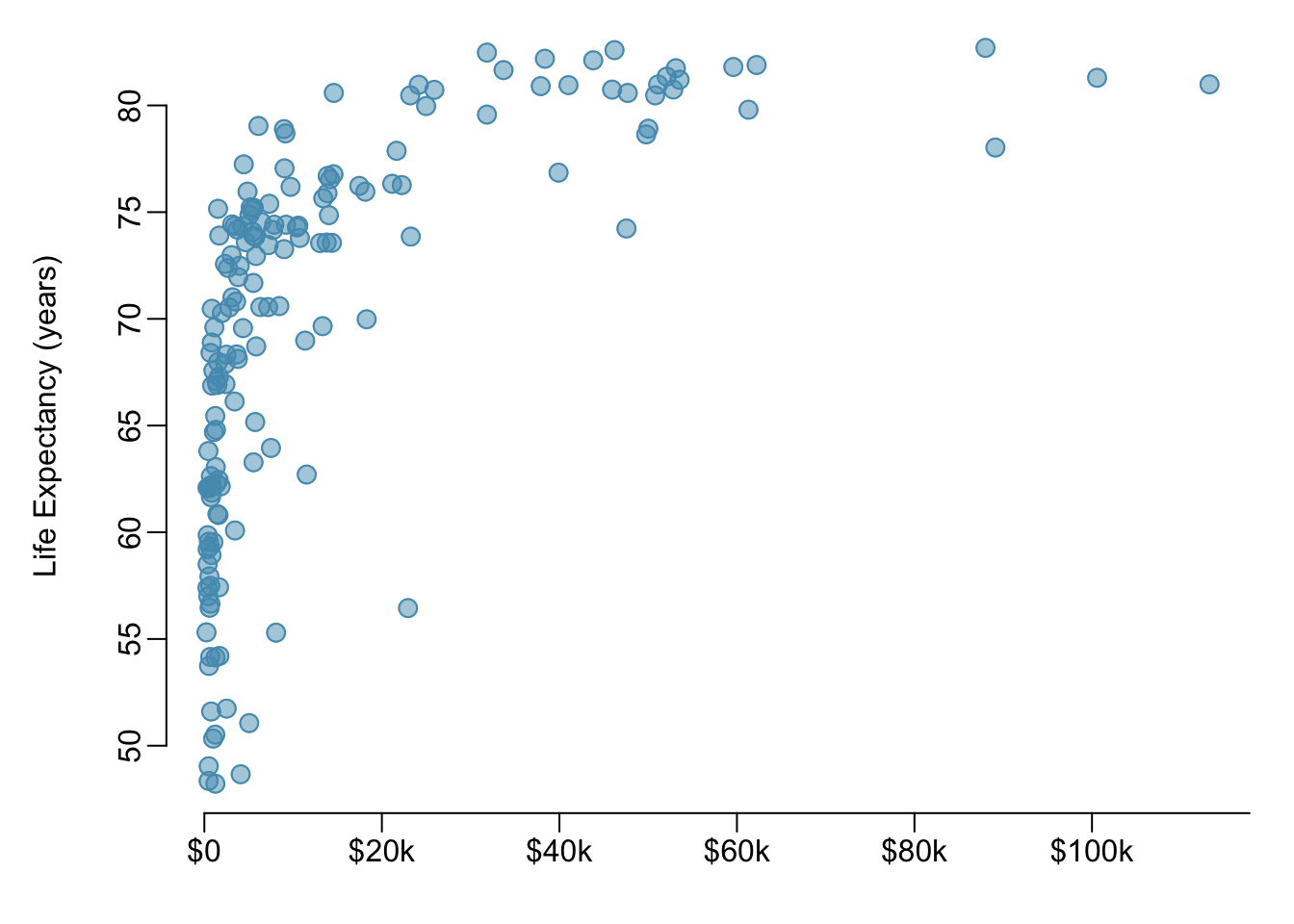
Figure 1.25: A scatterplot of life expectancy (years) versus annual per capita income (US dollars) in the wdi.2011 dataset from the oibiostat package.
1.6.1.2 Correlation
Correlation is a numerical summary statistic that measures the strength of a linear relationship between two variables. It is denoted by \(r\), which takes on values between -1 and 1.
If the paired values of two variables lie exactly on a line, \(r = \pm 1\); the closer the correlation coefficient is to \(\pm 1\), the stronger the linear association. When two variables are positively associated, with paired values that tend to lie on a line with positive slope, \(r > 0\). If two variables are negatively associated, \(r < 0\). A value of \(r\) that is 0 or approximately 0 indicates no apparent association between two variables.If paired values lie perfectly on either a horizontal or vertical line, there is no association and \(r\) is mathematically undefined.
The correlation coefficient quantifies the strength of a linear trend. Prior to calculating a correlation, it is advisable to confirm that the data exhibit a linear relationship. Although it is mathematically possible to calculate correlation for any set of paired observations, such as the life expectancy versus income data in Figure 1.25, correlation cannot be used to assess the strength of a nonlinear relationship.
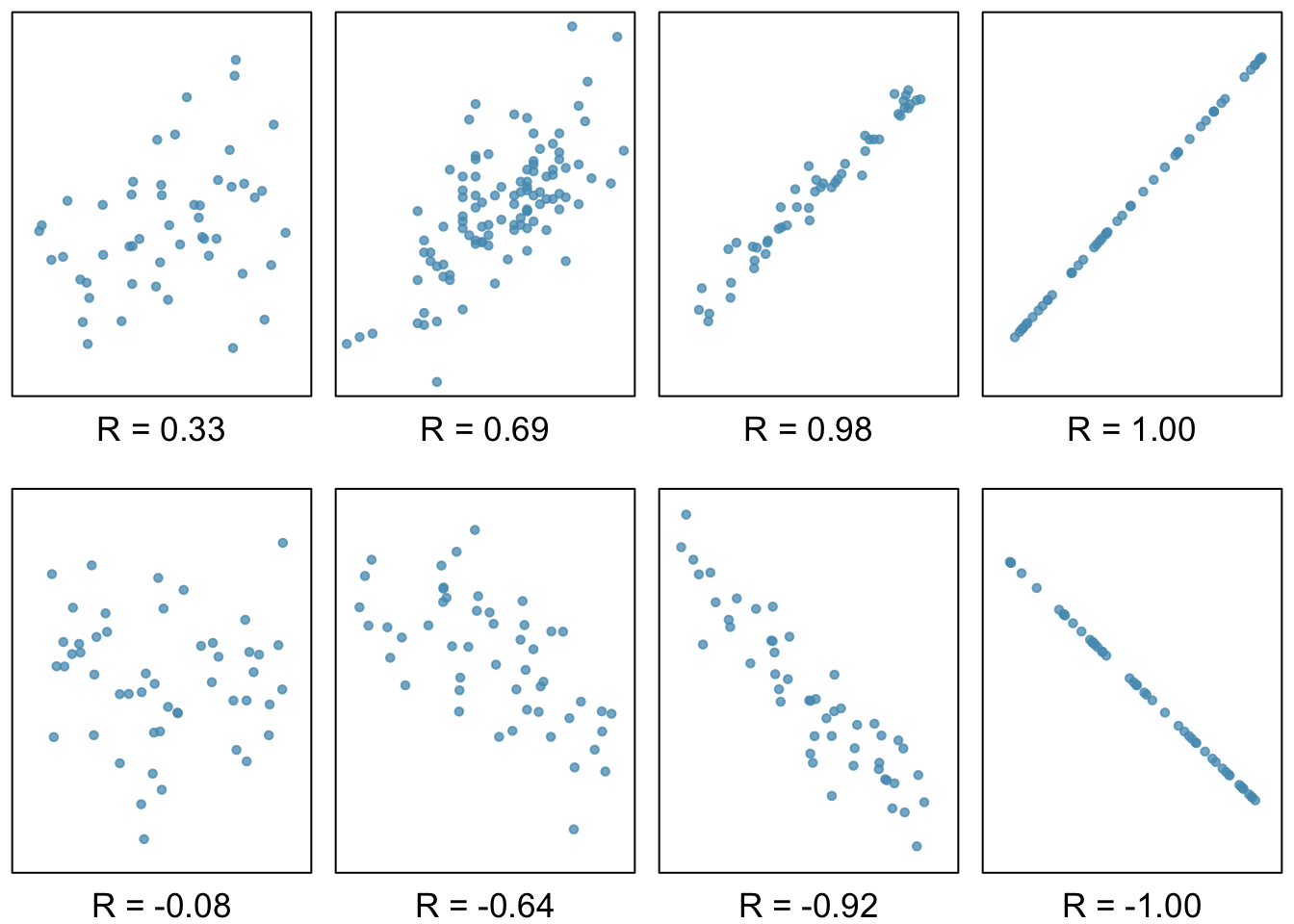
Figure 1.26: Scatterplots and their correlation coefficients. The first row shows positive associations and the second row shows negative associations. From left to right, strength of the linear association between \(x\) and \(y\) increases.
Definition 1.3 (Correlation) The correlation between two variables \(x\) and \(y\) is given by: \[r = \frac{1}{n-1}\sum^{n}_{i=1} \left(\frac{x_{i}-\overline{x}} {s_{x}}\right)\left(\frac{y_{i}-\overline{y}}{s_{y}}\right),\] where \((x_1,y_1), (x_2,y_2), \ldots, (x_n, y_n)\) are the \(n\) paired values of \(x\) and \(y\), and \(s_x\) and \(s_y\) are the sample standard deviations of the \(x\) and \(y\) variables, respectively.
Example 1.4 Calculate the correlation coefficient of \(x\) and \(y\), plotted in Figure 1.27. Calculate the mean and standard deviation for \(x\) and \(y\): \(\overline{x} = 2\), \(\overline{y} = 3\), \(s_x = 1\), and \(s_y = 2.65\).
\[\begin{align*} r &= \frac{1}{n-1}\sum^{n}_{i=1} \left(\frac{x_{i}-\overline{x}} {s_{x}}\right)\left(\frac{y_{i}-\overline{y}}{s_{y}}\right) \\ &= \frac{1}{3 - 1} \left[\left(\frac{1 - 2} {1}\right)\left(\frac{5 - 3}{2.65}\right) + \left(\frac{2 - 2} {1}\right)\left(\frac{4 - 3}{2.65}\right) + \left(\frac{3 - 2} {1}\right)\left(\frac{0 - 3}{2.65}\right) \right] \\ &= -0.94. \end{align*}\]
The correlation is -0.94, which reflects the negative association visible from the scatterplot in Figure 1.27.
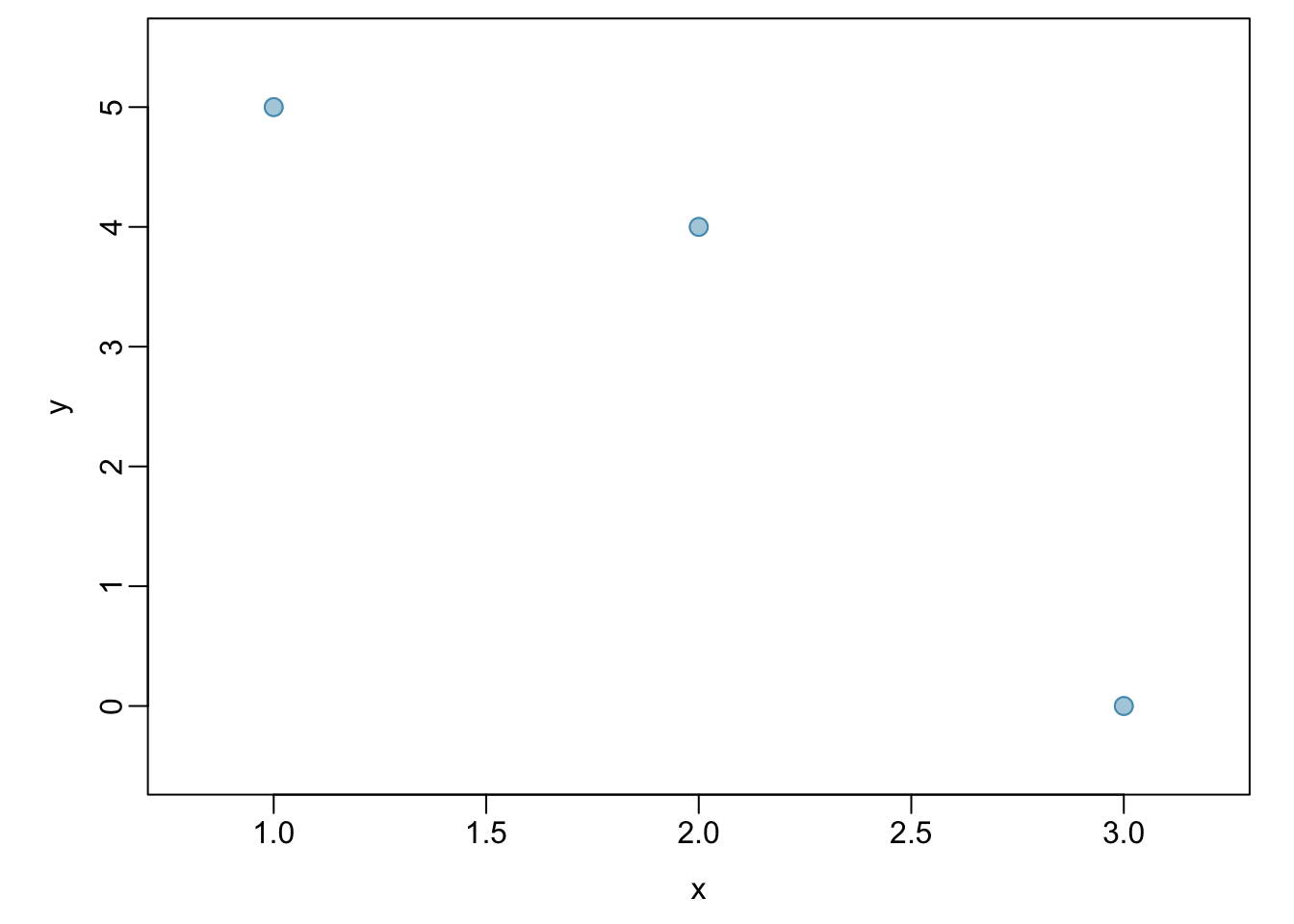
Figure 1.27: A scatterplot showing three points: (1, 5), (2, 4), and (3, 0)
Example 1.5 Is it appropriate to use correlation as a numerical summary for the relationship between life expectancy and income after a log transformation is applied to both variables? Refer to Figure 1.28.
Figure 1.28 shows an approximately linear relationship; a correlation coefficient is a reasonable numerical summary of the relationship. As calculated from statistical software, \(r = 0.79\), which is indicative of a strong linear relationship.
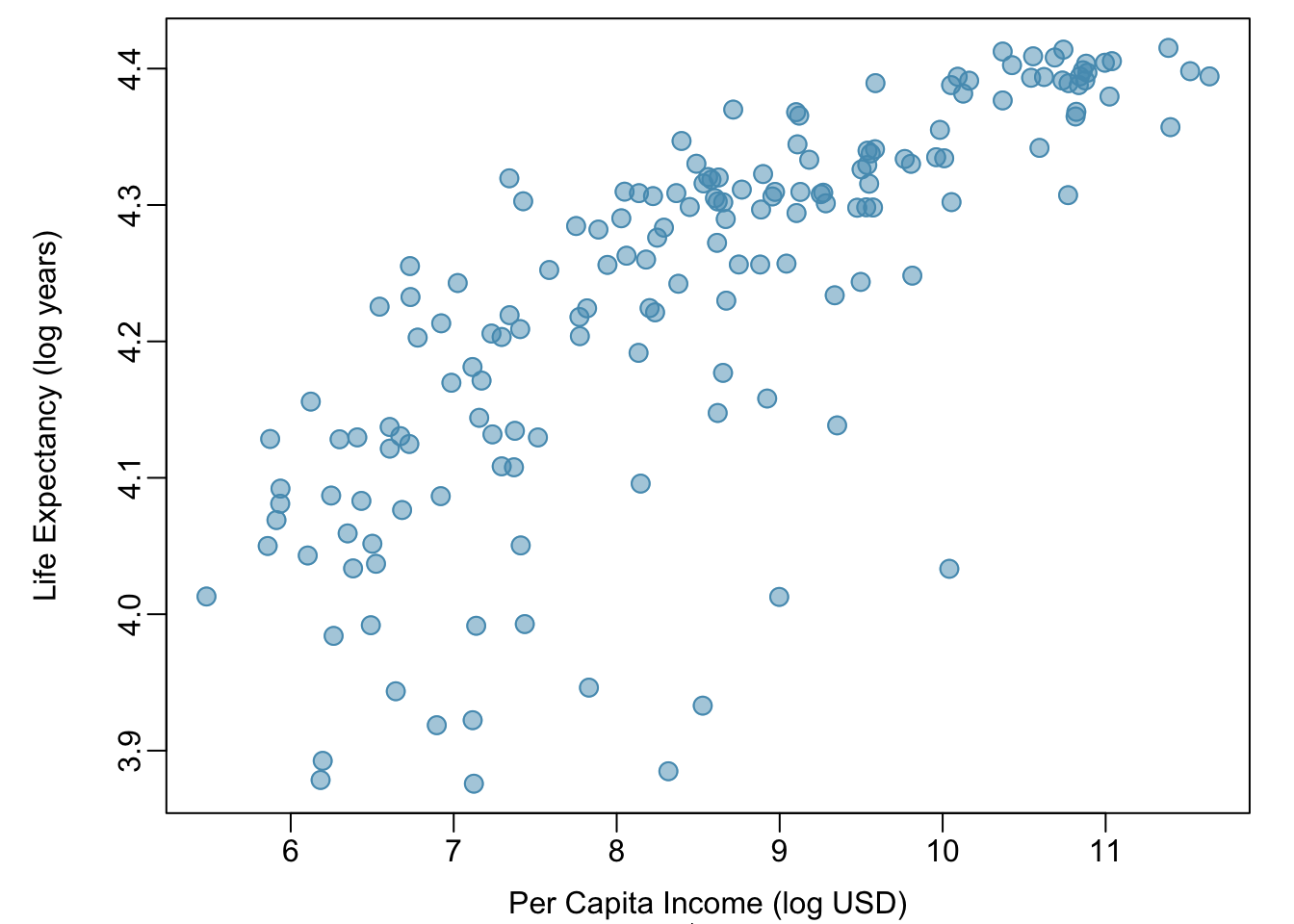
Figure 1.28: A scatterplot showing log(income) (horizontal axis) vs. log(life.expectancy) (vertical axis).
1.6.2 Two categorical variables
1.6.2.1 Contingency tables
A contingency table summarizes data for two categorical variables, with each value in the table representing the number of times a particular combination of outcomes occurs. Contingency tables are also known as two-way tables. Table 1.4 summarizes the relationship between race and genotype in the famuss data.
The row totals provide the total counts across each row and the column totals are the total counts for each column; collectively, these are the marginal totals.
| CC | CT | TT | Sum | |
|---|---|---|---|---|
| African Am | 16 | 6 | 5 | 27 |
| Asian | 21 | 18 | 16 | 55 |
| Caucasian | 125 | 216 | 126 | 467 |
| Hispanic | 4 | 10 | 9 | 23 |
| Other | 7 | 11 | 5 | 23 |
| Sum | 173 | 261 | 161 | 595 |
Like relative frequency tables for the distribution of one categorical variable, contingency tables can also be converted to show proportions. Since there are two variables, it is necessary to specify whether the proportions are calculated according to the row variable or the column variable.
Table 1.5 shows the row proportions for Table 1.4; these proportions indicate how genotypes are distributed within each race. For example, the value of 0.593 in the upper left corner indicates that of the African Americans in the study, 59.3% have the CC genotype.
| CC | CT | TT | Sum | |
|---|---|---|---|---|
| African Am | 0.5925926 | 0.2222222 | 0.1851852 | 1 |
| Asian | 0.3818182 | 0.3272727 | 0.2909091 | 1 |
| Caucasian | 0.2676660 | 0.4625268 | 0.2698073 | 1 |
| Hispanic | 0.1739130 | 0.4347826 | 0.3913043 | 1 |
| Other | 0.3043478 | 0.4782609 | 0.2173913 | 1 |
Table 1.6 shows the column proportions for Table 1.4; these proportions indicate the distribution of races within each genotype category. For example, the value of 0.092 indicates that of the CC individuals in the study, 9.2% are African American.
| CC | CT | TT | |
|---|---|---|---|
| African Am | 0.092 | 0.023 | 0.031 |
| Asian | 0.121 | 0.069 | 0.099 |
| Caucasian | 0.723 | 0.828 | 0.783 |
| Hispanic | 0.023 | 0.038 | 0.056 |
| Other | 0.040 | 0.042 | 0.031 |
| Sum | 1.000 | 1.000 | 1.000 |
Example 1.6 For African Americans in the study, CC is the most common genotype and TT is the least common genotype. Does this pattern hold for the other races in the study? Do the observations from the study suggest that distribution of genotypes at r577x vary between populations?
The pattern holds for Asians, but not for other races. For the Caucasian individuals sampled in the study, CT is the most common genotype at 46.3%. CC is the most common genotype for Asians, but in this population, genotypes are more evenly distributed: 38.2% of Asians sampled are CC, 32.7% are CT, and 29.1% are TT. The distribution of genotypes at r577x seems to vary by population.
Exercise 1.1 As shown in Table 1.6, 72.3% of CC individuals in the study are Caucasian. Do these data suggest that in the general population, people of CC genotype are highly likely to be Caucasian?
No, this is not a reasonable conclusion to draw from the data. The high proportion of Caucasians among CC individuals primarily reflects the large number of Caucasians sampled in the study – 78.5% of the people sampled are Caucasian. The uneven representation of different races is one limitation of the famuss data.
1.6.2.2 Segmented bar plots
A segmented bar plot is a way of visualizing the information from a contingency table. Figures 1.29 and 1.30 graphically displays the data from Table 1.4; each bar represents a level of actn3.r577x and is divided by the levels of race. Figure 1.30 uses the row proportions to create a standardized segmented bar plot.
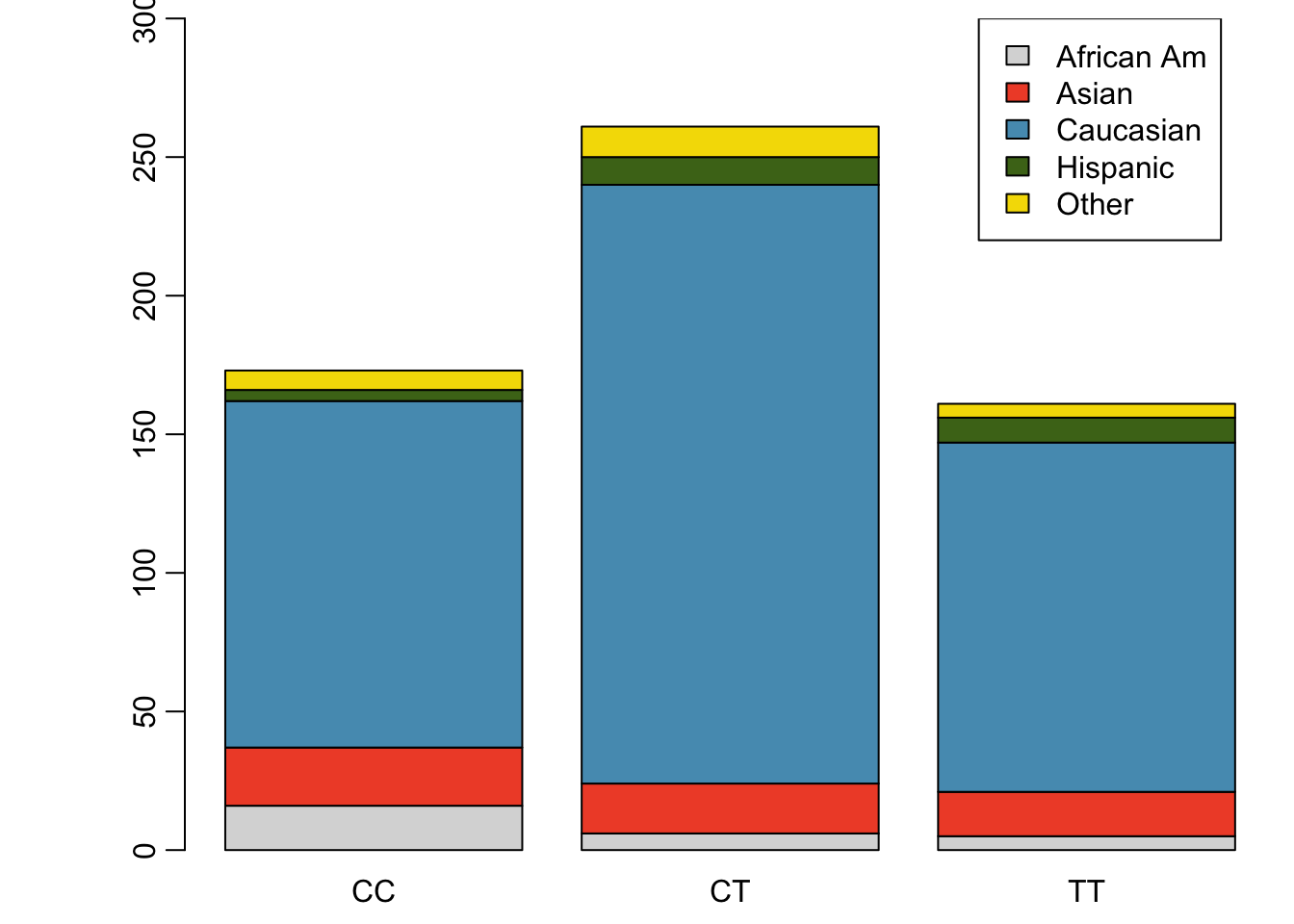
Figure 1.29: Segmented bar plot for individuals by genotype, with bars divided by race
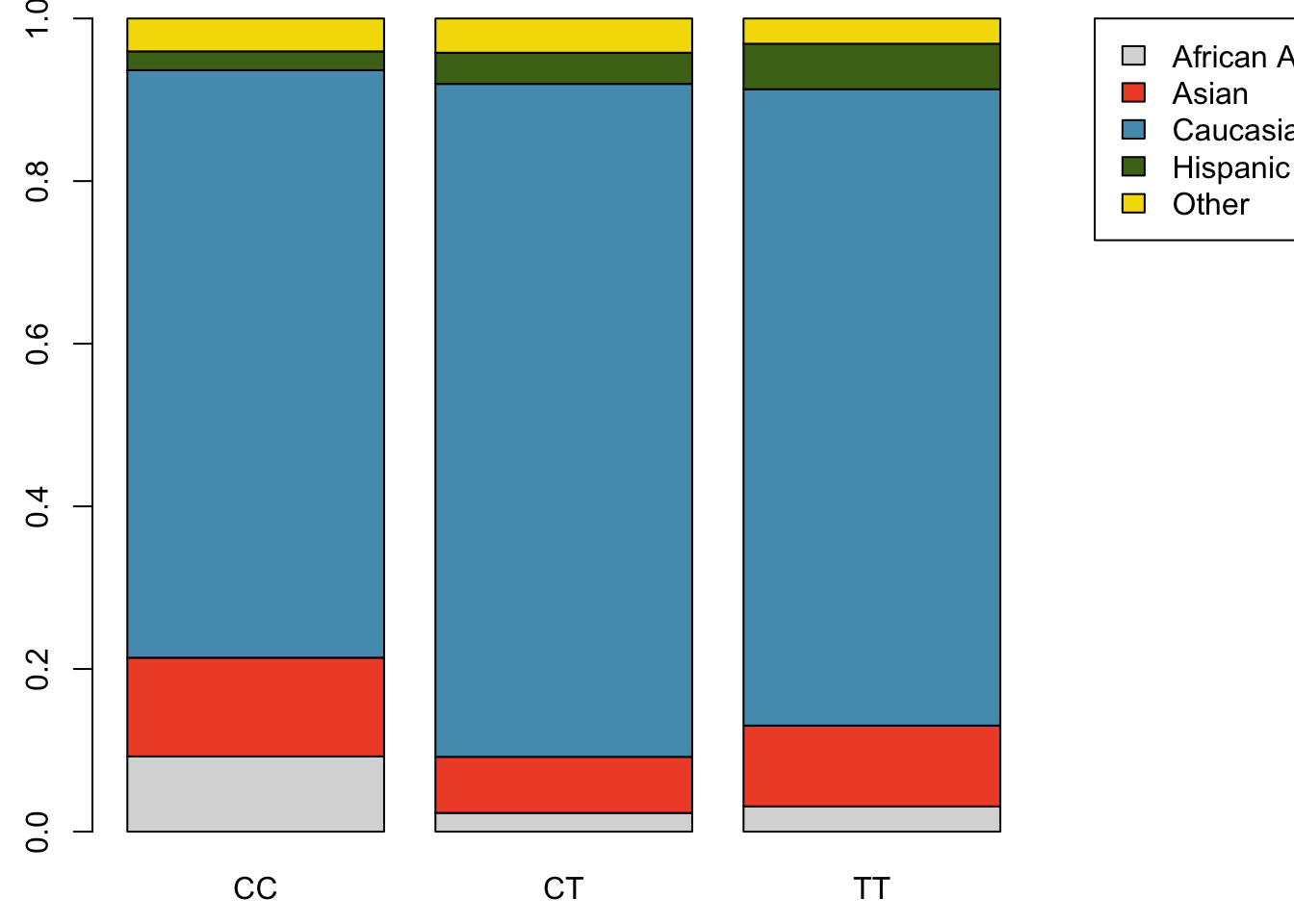
Figure 1.30: Standardized version of Figure 1.29
Alternatively, the data can be organized as shown in Figures 1.31 and 1.32, with each bar representing a level of race. The standardized plot is particularly useful in this case, presenting the distribution of genotypes within each race more clearly than in Figure 1.31.
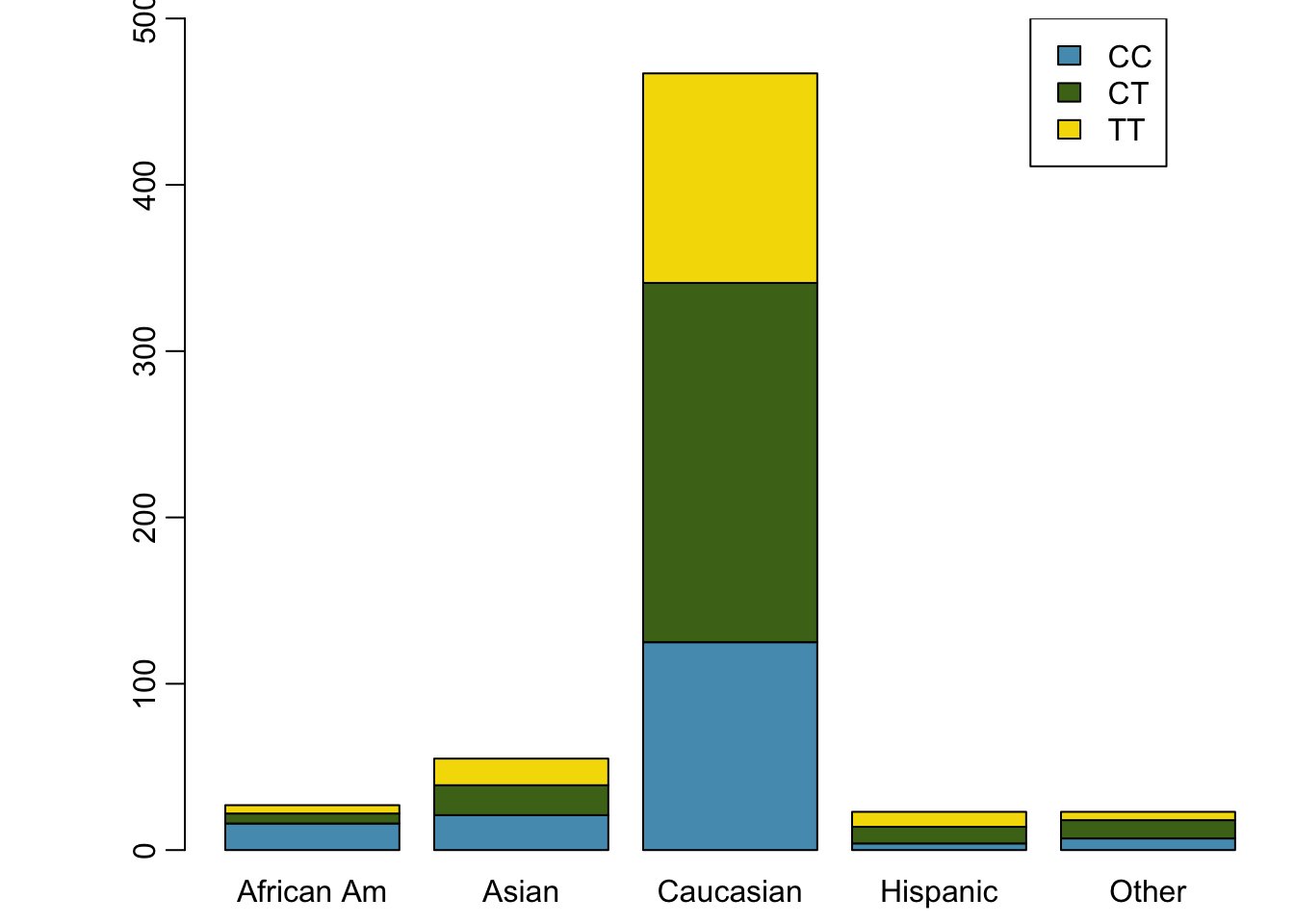
Figure 1.31: Segmented bar plot for individuals by race, with bars divided by genotype
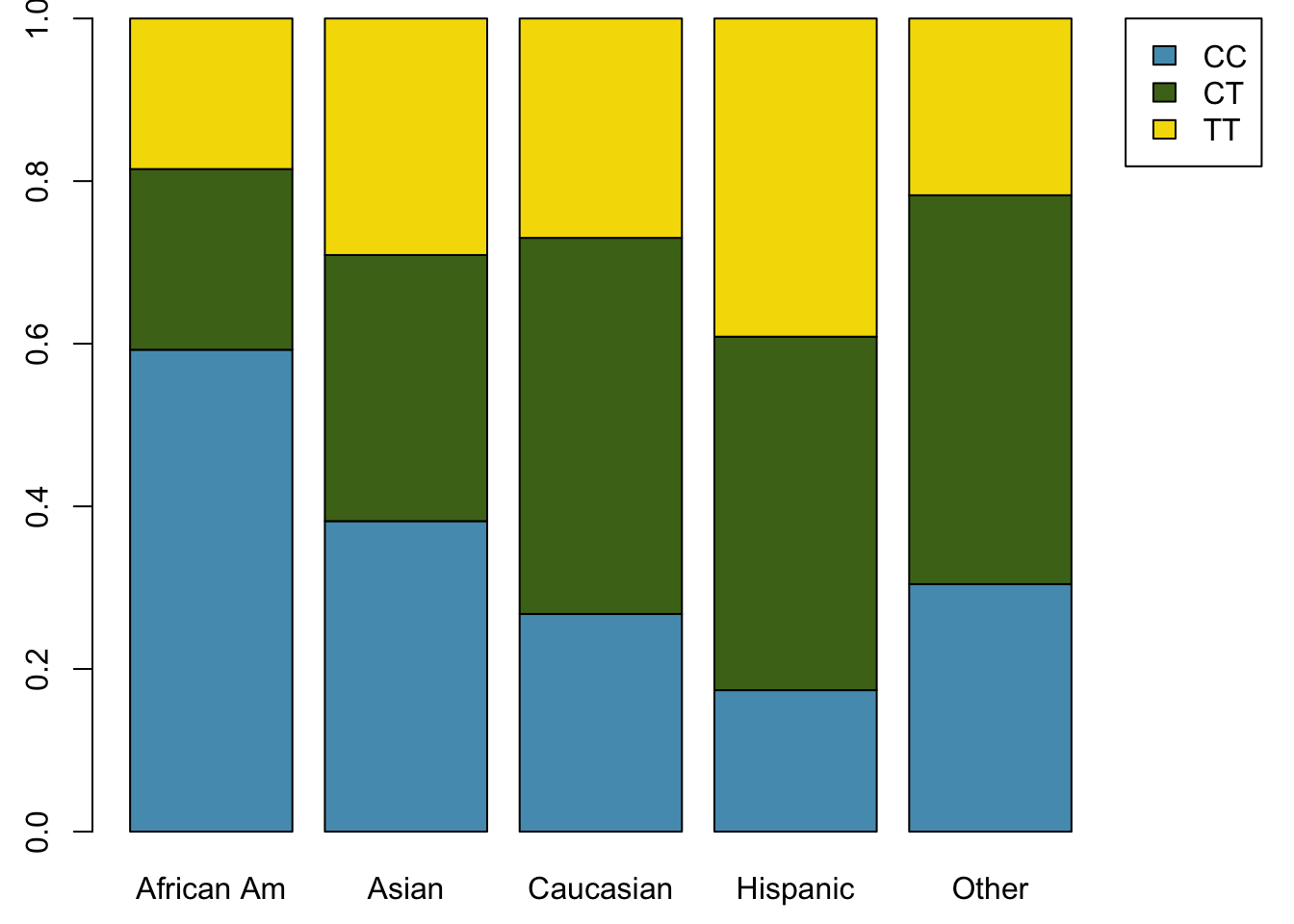
Figure 1.32: Standardized version of Figure 1.31